
Web Scraping com Beautiful Soup
Coletando dados de jogos populares do Backloggd desde a década de 80 usando Python + Beautiful Soup + Soup Sieve + Google Colab

Já viu um site com dados interessantes e teve vontade de ter eles em mãos? Neste texto, irei mostrar como apliquei o processo de Web Scraping em múltiplas páginas e obtive os dados sobre alguns dos jogos de videogames mais populares, utilizando a biblioteca Beautiful Soup, em Python.
O que é?
O Web Scraping, também chamado de raspagem de dados ou, em tradução livre, raspagem de rede, é uma técnica que consiste em extrair dados de páginas da web, mas que é feita de forma automatizada via código, ao invés de ser uma coleta manual. É um processo muito utilizado para monitorar informações em sites, coletar informações para análises, pesquisas acadêmicas, criar bases de dados para treinar modelos de aprendizado de máquina, entre outros.
Etapas do Web Scraping
Esse processo pode ser resumido em algumas etapas, sendo elas:
- Obter o conteúdo da página web
- Analisar o conteúdo da página obtida
- Extrair informações
Abaixo, irei mostrar como apliquei essas etapas para coletar informações.
Extraindo dados de jogos
Para este projeto, minha ideia foi extrair dados do site Backloggd, que é um site focado em mostrar diversas informações sobre videogames, desde os mais recentes, até os mais antigos.
1ª Etapa: obter o conteúdo da página web
Nesta etapa, cria-se a estratégia inicial para buscar o conteúdo dos sites, tendo como principal objetivo escolher a(s) página(s) correta(s) para a posterior extração dos seus dados.
Primeiro, define-se o objetivo, que aqui é a coleta de informações sobre jogos. Após isso, precisa-se explorar um pouco o site a fim de encontrar onde está o que precisa ser extraído.
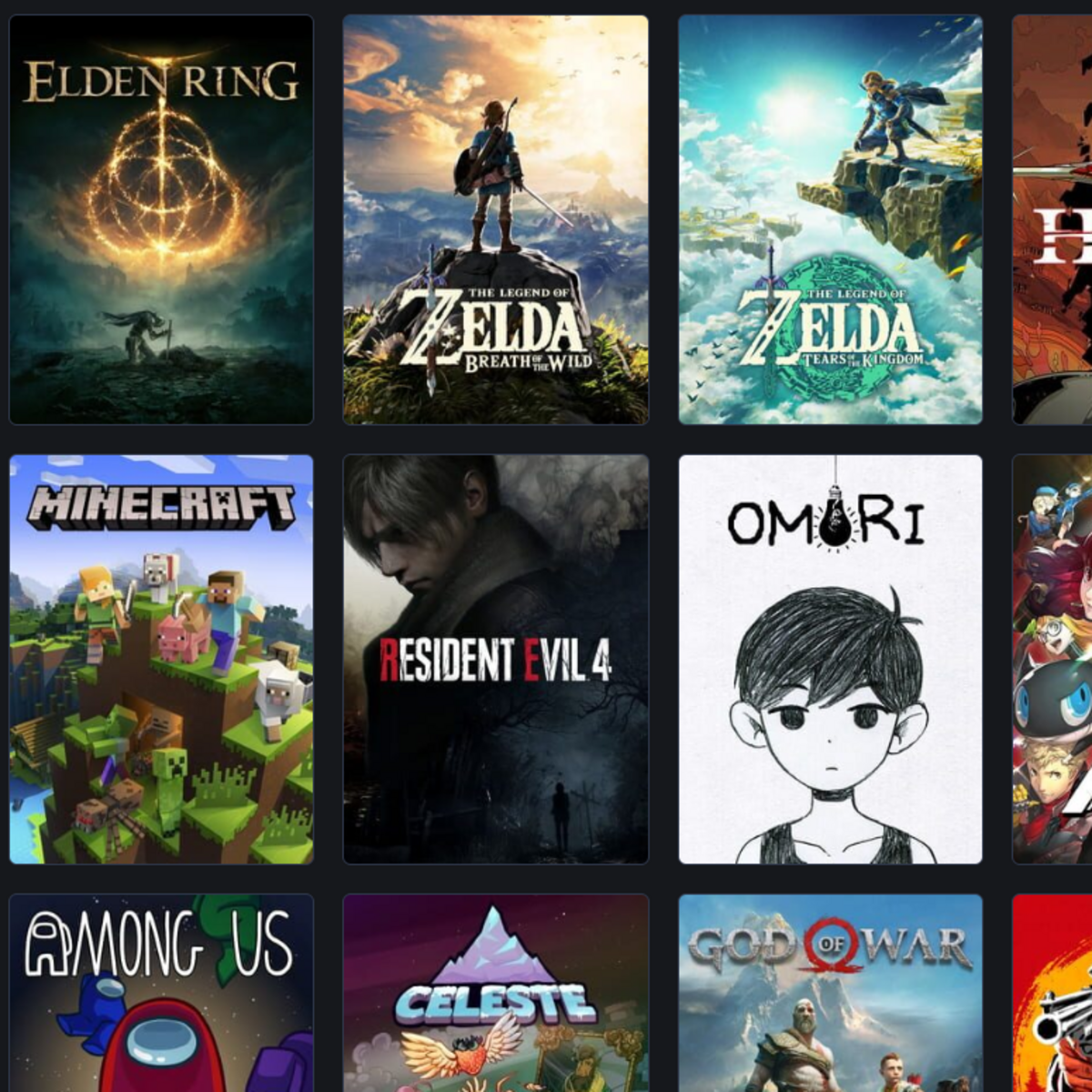
Explorando o site Backloggd, percebe-se que cada jogo possui uma página própria com suas informações, mas como o eu desejo obter os dados de vários jogos, precisa-se encontrar uma forma de acessar todas as páginas dos jogos. Por sorte, a plataforma possui uma página assim:
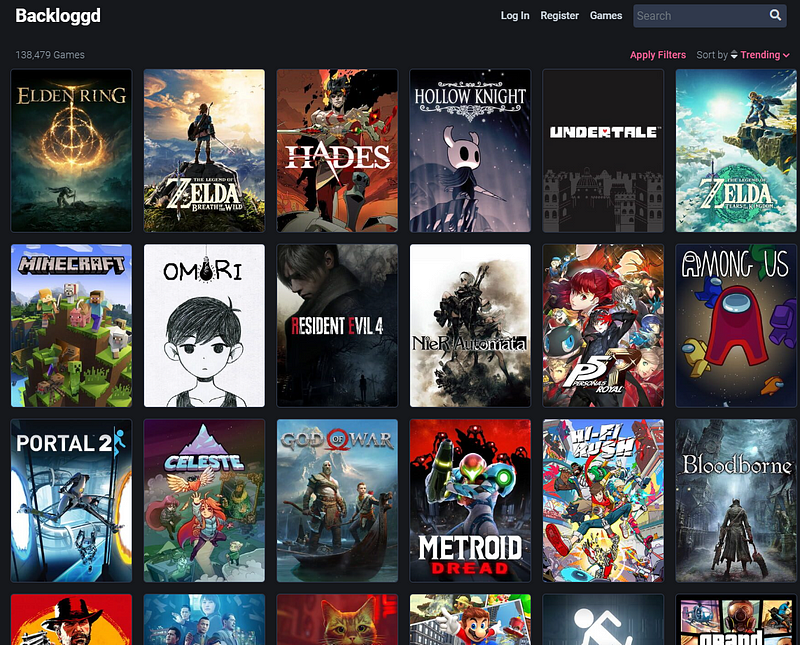
Página com diversas imagens dos jogos
Ao clicar na imagem de um jogo, o site te leva para uma página com informações :
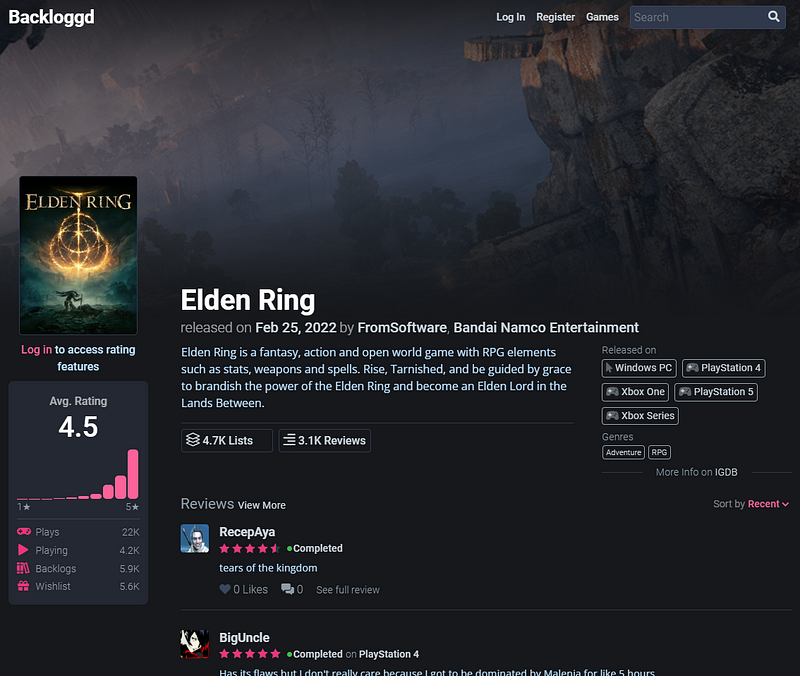
Página de um jogo, mostrando suas informações.
Portanto, a estratégia definida foi:
- Acessar a página com todos os jogos do site (link);
- Coletar os links de todos os jogos;
- Passar por cada um dos links, extraindo as informações do respectivo jogo.
Utilizando Python e sua biblioteca requests, pode-se obter o conteúdo da página (seu código fonte), conforme código abaixo.
import requests
url = "https://www.backloggd.com/games/lib/popular?page="
response = requests.get(url)
print(response.content)
Acima, uma imagem de como a saída do código é: um texto de uma só linha, armazenando todo o código fonte da url que foi feita a requisição. Dessa forma, tem-se em mãos o conteúdo de uma das páginas — esse é o passo inicial para o Web Scraping.
2ª Etapa: analisar o conteúdo da página obtida
Agora que já se tem uma estratégia definida e quais URLs serão utilizadas de base para realizar o processo, uma análise dessas páginas é necessária, a fim de traçar um passo a passo para, na etapa final, extrair apenas as informações que iremos precisar.
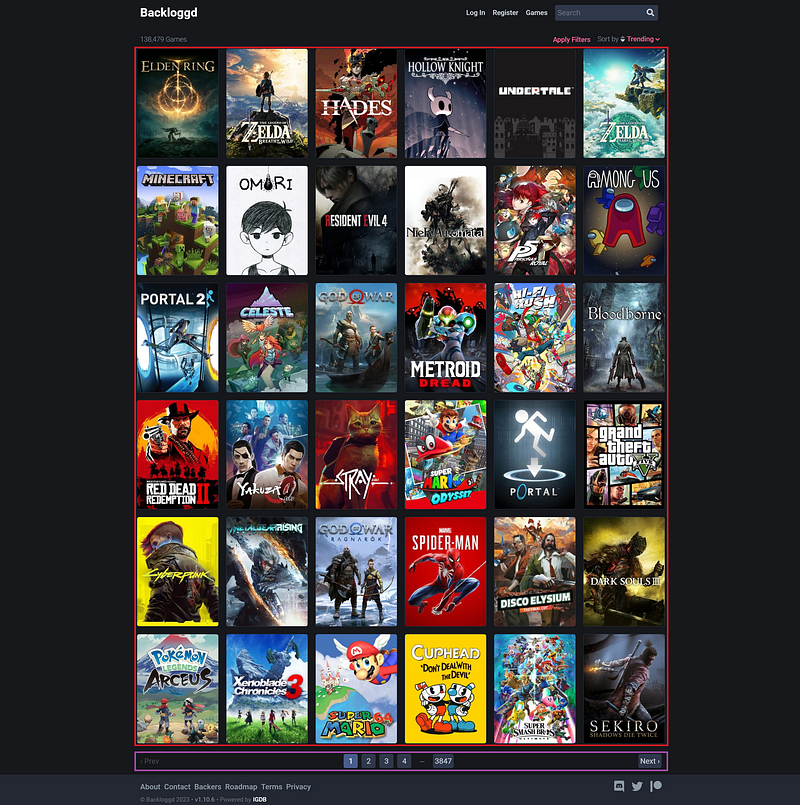
Primeiro, analisando a imagem acima (página onde os links serão extraídos), existem duas partes importantes que foram marcadas:
- Marcado com um retângulo vermelho, estão os jogos, sendo que através deles é possível obter os links para a sua página individual, conforme já falado anteriormente;
- Marcado com um retângulo roxo, há informações sobre as páginas, com essas informações você consegue buscar o restante dos jogos e seus links.
Essa etapa pode ser feita cada vez que você precisar extrair um novo dado, sempre analisando a página para depois trabalhar em cima dela.
3ª Etapa: extrair informações
A partir daqui, com o conteúdo analisado, pode-se dar início ao código para extrair as informações da página.
Mas como é possível extrair esses dados?
Na primeira etapa, todo o código fonte da página foi armazenado dentro da variável response e, através dela, com a ajuda das bibliotecas Beautiful Soup e Soup Sieve, pode-se buscar elementos específicos, como os que foram marcados na imagem acima.
Obs.: Em versões mais recentes da biblioteca Beautiful Soup, não é mais necessário o uso da Soup Sieve, pois ela já é implementada por padrão.
Primeiro, precisamos transformar o conteúdo da variável response em um objeto Beautiful Soup, para que possa ser interpretado pelas bibliotecas. Isso pode ser feito com o código abaixo:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
print(soup)
Acima, uma parte da saída do código, guardada na variável soup — observe que, diferente de antes, agora não é mais um texto de uma só linha, mas sim um HTML formatado e mais legível.
Inspecionando o que foi obtido, pode-se navegar pelos elementos da página, buscando por tags HTML, ID’s e seletores CSS que sirvam para encontrar os elementos que procuramos — no caso, os links e as informações sobre o número de páginas.
Dica: utilize a ferramenta de desenvolvedor (Dev Tools) do seu navegador para procurar de uma forma mais fácil onde está o elemento que você quer buscar.
Buscando pelas páginas
Pela URL do site é possível perceber que conforme a página muda, o parâmetro page da URL também muda. Por exemplo:
- Página 2: URL = https://www.backloggd.com/games/lib/popular?page=2
- Página 3: URL = https://www.backloggd.com/games/lib/popular?page=3
Ou seja, apenas buscando o número total de páginas, já é possível saber quantas páginas precisaremos percorrer para executar 100% do código. Por sorte, há um elemento na parte de baixo do site que indica isso:

Pela ferramenta de desenvolvedor do meu navegador (Google Chrome), consigo visualizar esse elemento e saber sua tag e suas classes.
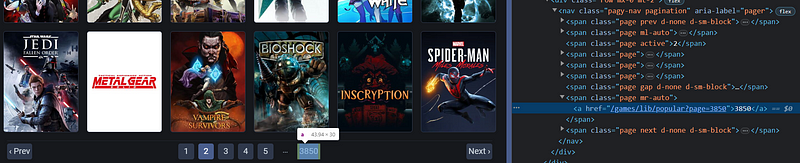
Analisando um elemento pelo Dev Tools do Google Chrome
Ou seja, localizado dentro de uma tag navigation (nav), com a classe “pagination”, sendo a penúltima tag âncora (a), está o botão com o número total de páginas. Para selecioná-lo, basta utilizar o código abaixo, que busca o elemento com o total de páginas através de um seletor CSS e, por fim, extrai seu número.
import soupsieve as sv
# seletor CSS para localizar o botão
css_pagination_selector = 'nav.pagination > span:nth-last-child(2) > a'
# selecionando o botão e extraindo seu número
pagination_button = sv.select_one(css_pagination_selector, soup)
num_pages = int(pagination_button.text)Buscando pelos links
Similar ao que foi mostrado anteriormente, agora os links dos jogos serão obtidos. Algo importante a se fazer é buscar primeiro todos os links de apenas uma página e, caso funcione, aplicar o mesmo código para todo o resto.
# seletor CSS para localizar os elementos com links
css_link_selector = 'div.col-2.my-2.px-1.px-md-2 > a [href]'
links = sv.select(css_link_selector, soup)
print(links)Novamente, através de um seletor CSS, pode-se encontrar os links da página. Dessa vez, note que o método utilizado foi sv.select, fazendo com que todos os elementos que se encaixam no seletor sejam selecionados. Abaixo, a saída da variável links:
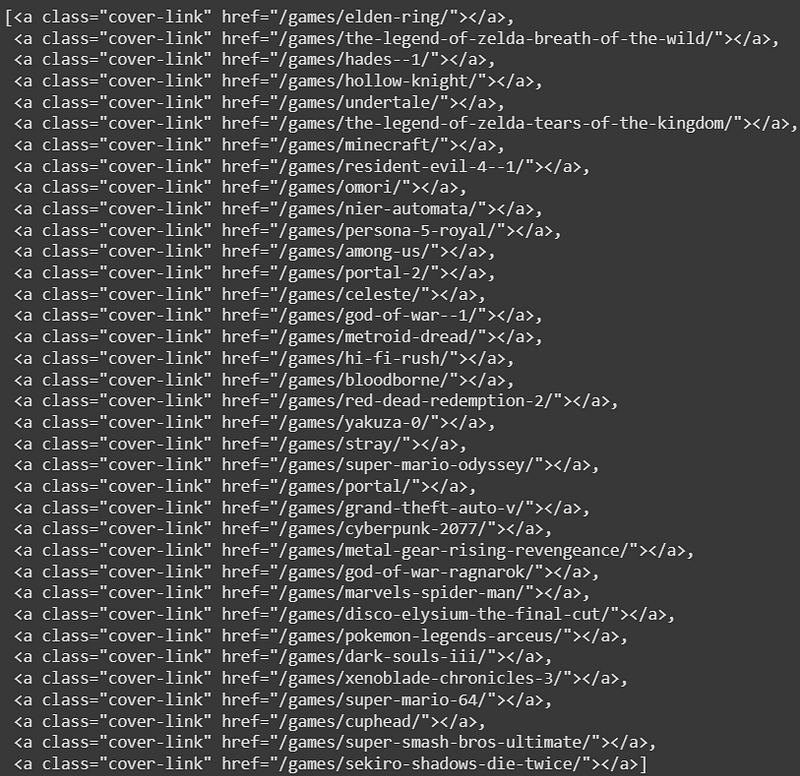
Obtendo o href da tag a, junto com a URL base para encontrar os jogos, conseguimos formar a URL completa para localizar cada um dos jogos. Com o seguinte código isso pode ser feito:
base_url = 'https://www.backloggd.com'
game_links = [f"{base_url}{link['href']}" for link in links]
print(game_links)Agora a variável game_links guarda uma lista com todos os links dos jogos:
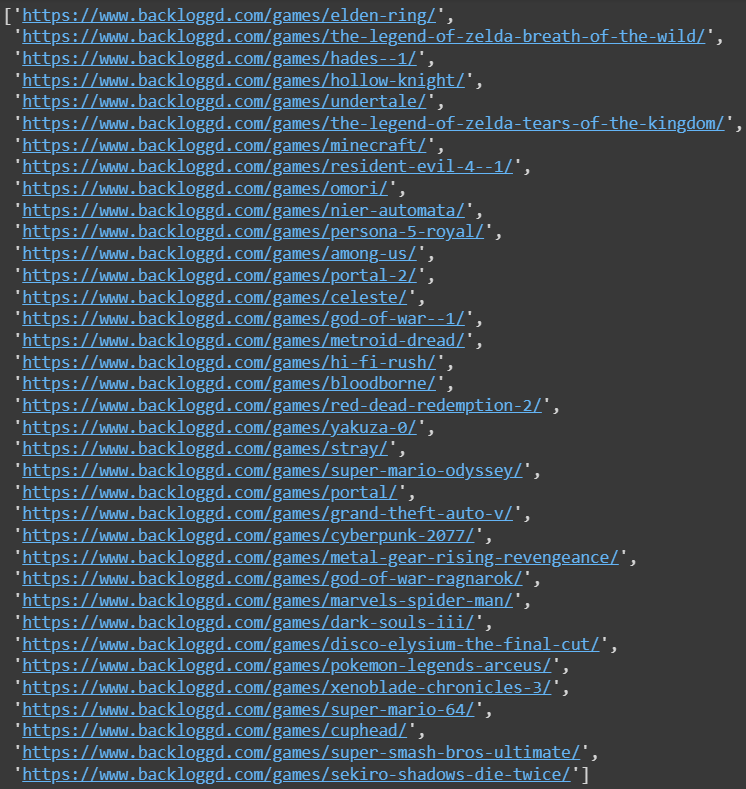
Esse foi o código para obter os valores da primeira página de jogos do site. Tendo conhecimento que o código deu certo, podemos generalizá-lo para todas as outras páginas, obtendo todos os links para, posteriormente, passar pelos links e buscar as informações de cada jogo. Isso pode ser feito com um loop em junção com o valor da variável num_pages, obtida anteriormente:
base_url = 'https://www.backloggd.com'
css_link_selector = 'div.col-2.my-2.px-1.px-md-2 > a [href]'
game_links = []
for page in range(1, num_pages + 1):
page_response = requests.get(f'{url}{page}')
# obtendo os links da página atual
soup = BeautifulSoup(page_response.content, "html.parser")
links = sv.select(css_link_selector, soup)
# extendendo a lista, inserindo novos jogos a cada loop
game_links.extend(f"{base_url}{link['href']}" for link in links)O código acima deveria executar normalmente, mas não irá, por conta de que alguns erros que podem acontecer e não há nenhum tratamento quanto a isso. Além disso, é bom termos uma noção de quanto tempo o loop irá demorar para ser executado, pois o ato de realizar requisições em diversas URLs não é algo tão rápido. Em seguida, irei mostrar como resolver esses problemas.
Segurança e tratamentos no Web Scraping
Cada resposta de requisição possui um código de status HTTP (também conhecido como response status code), que irá indicar se a requisição foi concluída corretamente. Neste texto não entrarei profundamente nesse assunto, mas recomendo consultar a documentação do MDN sobre isso.
No caso de Web Scraping, três casos de status code são bem comuns:
- Código 200 (Ok): indica que a requisição foi feita corretamente, a partir disso se executa o restante do código;
- Código 429 (Too Many Requests): indica que muitas requisições foram feitas em um curto período de tempo, sendo necessário esperar um pouco até fazer outra;
- Código 403 (Forbidden): indica que quem fez a requisição não possui direitos de acesso ao conteúdo.
A melhor forma de lidar com o código 429 é aumentando o tempo entre cada requisição, geralmente colocando um atraso de 0.5 a 1 segundo entre cada uma. Por mais que essa medida aumente o tempo de execução do código, é errado tentar burlar isso, pois diversas requisições em um mesmo servidor podem ser prejudiciais para ele, agindo como ataques ao servidor.
Isso pode ser feito utilizando a biblioteca time e seu método sleep:
import time
# aguarda 0.75 segundos para rodar a próxima linha
time.sleep(0.75)
print("Este texto irá aparecer após 0.75 segundos")Para ter uma melhor percepção do tempo, pode-se utilizar a biblioteca tqdm, responsável por criar uma barra de progresso no loop.
Já o código 403, pode ser causado por conta de que você realmente não possui acesso ao site, precisando de autorização para o acessar, mas também pode ser que o site te detectou como um robô de Web Scraping e te proibiu de acessar seu conteúdo. Nesse segundo caso, uma das formas de solucioná-lo é alterando o cabeçalho (header) da requisição, colocando um User Agent (UA) confiável nele. O UA ajuda os servidores web a identificar o tipo de navegador (ou se é um bot) da requisição, então alterá-lo pode ajudar a evitar esse status code.
Abaixo, uma abordagem comum para resolver o problema, criando alguns UA’s no código, selecionando um aleatoriamente e inserindo-o no cabeçalho da requisição:
import random
# lista com alguns UA's
user_agent_list = ['Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 13_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.1 Safari/605.1.15',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:15.0) Gecko/20100101 Firefox/15.0.1']
# escolhendo aleatoriamente um UA
user_agent = random.choice(user_agent_list)
headers = {'User-Agent': user_agent}
response = requests.get(base_url, headers=headers)Cada servidor web possui uma segurança diferente e talvez mais ou menos etapas sejam necessárias para conseguir realizar todas as etapas do Web Scraping. No caso desse site, apenas essas duas medidas foram suficientes.
Além desses códigos, também se faz interessante adicionar uma verificação para interromper o loop caso o status code seja diferente de 200, dessa forma é possível visualizar caso um erro diferente ocorra. No final, o código para buscar os links ficará dessa forma:
base_url = 'https://www.backloggd.com'
css_link_selector = 'div.col-2.my-2.px-1.px-md-2 > a [href]'
game_links = []
for page in tqdm(range(1, num_pages + 1)):
# evitando o erro 403 - header com UA
user_agent = random.choice(user_agent_list)
header = {'User-Agent': user_agent}
page_response = requests.get(f'{url}{page}', headers=header)
if page_response.status_code != 200:
print(f"Page: {page}\nCode: {page_response.status_code}\nUA: {user_agent}")
break
# obtendo os links da página atual
soup = BeautifulSoup(page_response.content, "html.parser")
links = sv.select(css_link_selector, soup)
# extendendo a lista, inserindo novos jogos a cada loop
game_links.extend(f"{base_url}{link['href']}" for link in links)
# evitando o erro 429 - atraso no loop
time.sleep(0.8)No final, a variável game_links terá todos os links dos jogos.
Extraindo dados dos jogos
Similar ao que foi feito na primeira etapa ao buscar pelos links, precisa-se entrar na página de um jogo e observar quais informações queremos selecionar para serem extraídas.
Abaixo, uma imagem mostrando os dados que foram selecionados, destacando-os com retângulos coloridos, onde cada cor representa um tipo de dado diferente a ser buscado. As informações selecionadas dependem muito do objetivo do projeto. No meu caso, não quis buscar a imagem do jogo e nem comentários (avaliações) de usuários.
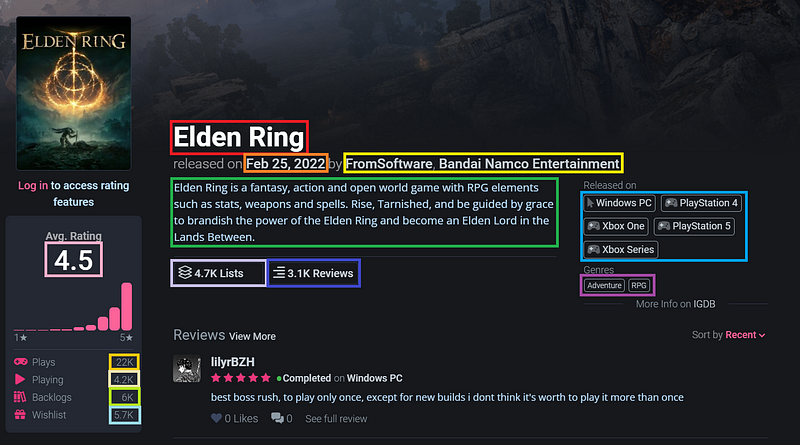
Foi decidido, então, que o Web Scraping será aplicado para pegar 13 informações diferentes sobre cada jogo, sendo elas:
- Title: título/nome do jogo;
- Release Date: data de lançamento;
- Developers: desenvolvedores ou empresas desenvolvedoras do jogo;
- Summary: sinopse do jogo;
- Platforms: plataformas em que o jogo foi lançado;
- Genres: gêneros que o jogo possui;
- Rating: nota média do jogo;
- Plays: quantidade de vezes que o jogo foi jogado;
- Playing: quantidade de pessoas jogando o jogo;
- Backlogs: quantidade de vezes que o jogo foi comprado, mas ainda não jogado;
- Wishlist: quantidade de vezes que o jogo foi adicionado na lista de desejos;
- Lists: quantidade de vezes que o jogo foi listado (falado sobre) no site;
- Reviews: número de comentários (avaliações) que o jogo recebeu.
Para guardar esses dados, foi decidido utilizar a biblioteca Pandas, armazenando as informações em uma estrutura tabular (data frame) e facilitando a sua visualização. Primeiramente, foi preciso criar a tabela com suas colunas:
import pandas as pd
cols = ['Title', 'Release_Date', 'Developers', 'Summary', 'Platforms', 'Genres', 'Rating', 'Plays', 'Playing', 'Backlogs', 'Wishlist', 'Lists', 'Reviews']
df_games = pd.DataFrame(columns=cols)Agora, da mesma forma que foi feito anteriormente para extrair dados dos links, o mesmo será aplicado aos dados dos jogos, mas agora utilizando a variável game_links para realizar o loop e df_games para guardar os resultados obtidos.
for link in tqdm(game_links):
# evitando o erro 403 - header com UA
user_agent = random.choice(user_agent_list)
header = {'User-Agent': user_agent}
game_response = requests.get(link, headers=header)
if game_response.status_code != 200:
print(f"Link: {link}\nStatus: {game_response.status_code}\nUA: {user_agent}")
break
soup = BeautifulSoup(game_response.content, "html.parser")
# coletando dados do jogo
title = sv.select_one('#title h1', soup).text
release_date = sv.select_one('.sub-title a', soup).text
developers_element = sv.select_one('.col-auto.pl-lg-1.sub-title', soup)
developers = [i.text.strip() for i in developers_element.select('a')]
summary = sv.select_one('#collapseSummary', soup).text.strip()
platforms = [i.text.strip() for i in sv.select('.game-page-platform', soup)]
genres = [i.text.strip() for i in sv.select('.genre-tag', soup)]
rating = sv.select_one('#score > h1', soup).text
plays, playing, backlogs, wishlist = [i.text.strip() for i in sv.select('.col-auto.ml-auto.pl-0 p', soup)]
lists, reviews = [i.text.strip().split()[0] for i in sv.select('.game-page-sidecard', soup)]
# adicionando uma nova linha no data frame com os dados
row = [title, release_date, developers, summary, platforms, genres, rating, plays, playing, backlogs, wishlist, lists, reviews]
df_games.loc[len(df_games)] = row
# evitando erro 429 - atraso no loop
time.sleep(0.75)Tratando possíveis erros
Ao coletar os dados dos jogos, existem duas ocasiões onde a página pode acabar não fornecendo todas as informações necessárias. Nesses casos, vale observar possíveis erros e resolvê-los.
Primeiramente, o site sofre diversas atualizações, então é possível que um jogo seja removido e sua URL não seja encontrada. Isso seria encontrado facilmente caso um status code 404 (Not Found — Página não encontrada) fosse retornado da requisição, mas, no caso desse site, ele retorna um código 200 e uma página contendo algumas informações:
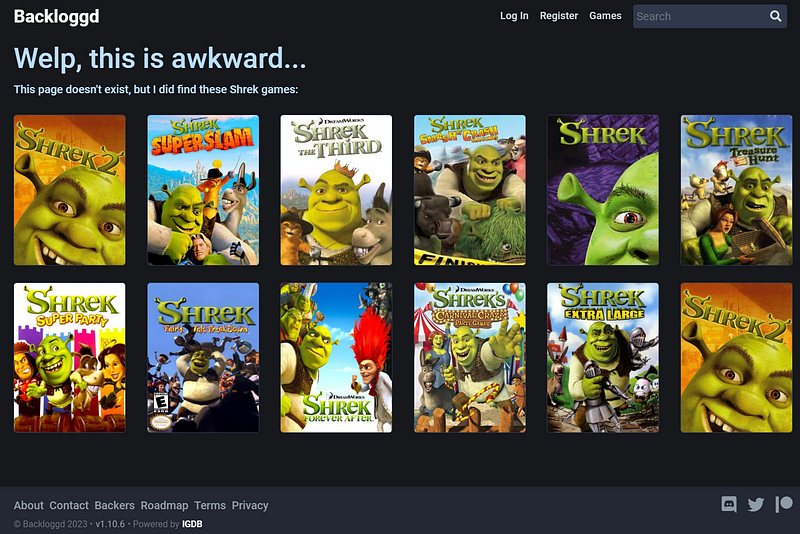
Página não encontrada
Nestes casos onde o status code não é correto, o que pode ser feito é analisar o conteúdo da página, procurando por uma mensagem que consiga indicar que a página não foi encontrada. Acima, tem-se um texto “Welp, this is awkward…”, que faz esse papel. Então, pode-se colocar uma condicional para procurar esse texto e, caso ele exista, pular para o próximo jogo, pois não existem informações a serem buscadas.
Além disso, existem alguns jogos que não possuem a tag sobre seus desenvolvedores, gerando erros caso você tente obter essa informação. Então isso também precisa ser tratado.
No final, então, o código ficará assim:
for link in tqdm(game_links):
# evitando o erro 403 - header com UA
user_agent = random.choice(user_agent_list)
header = {'User-Agent': user_agent}
game_response = requests.get(link, headers=header)
if game_response.status_code != 200:
print(f"Link: {link}\nStatus: {game_response.status_code}\nUA: {user_agent}")
break
soup = BeautifulSoup(game_response.content, "html.parser")
# verificando há erro de página não encontrada
if 'Welp, this is awkward...' not in game_response.text:
# coletando dados do jogo
title = sv.select_one('#title h1', soup).text
release_date = sv.select_one('.sub-title a', soup).text
developers_element = sv.select_one('.col-auto.pl-lg-1.sub-title', soup)
# abaixo, um 'if' foi adicionado para verificar se há informação a ser selecionada
developers = [i.text.strip() for i in developers_element.select('a')] if developers_element else []
summary = sv.select_one('#collapseSummary', soup).text.strip()
platforms = [i.text.strip() for i in sv.select('.game-page-platform', soup)]
genres = [i.text.strip() for i in sv.select('.genre-tag', soup)]
rating = sv.select_one('#score > h1', soup).text
plays, playing, backlogs, wishlist = [i.text.strip() for i in sv.select('.col-auto.ml-auto.pl-0 p', soup)]
lists, reviews = [i.text.strip().split()[0] for i in sv.select('.game-page-sidecard', soup)]
# adicionando uma nova linha no data frame com os dados
row = [title, release_date, developers, summary, platforms, genres, rating, plays, playing, backlogs, wishlist, lists, reviews]
df_games.loc[len(df_games)] = row
# evitando erro 429 - atraso no loop
time.sleep(0.75)Salvando as informações
A tabela com as informações dos jogos será armazenada dentro de df_games, agora com a possibilidade de ser transformada em um arquivo:
df_games.to_csv("backloggd_games.csv")Com o código acima, um arquivo chamado “backloggd_games.csv” será criado, armazenando a tabela com as informações dos jogos.
Além disso, como o Web Scraping é um processo que pode ser bem demorado, é útil tentar salvar os dados obtidos para, caso algo inesperado aconteça (internet caia, erros no site, precise recomeçar o código, etc.), você não perderá os dados já obtidos. As variáveis podem ser salvas com a biblioteca pickle e, caso esteja em um ambiente de desenvolvimento temporário, como o Google Colaboratory, salvar os dados no Google Drive se torna uma boa opção.
import pickle
caminho_do_arquivo = "/content/drive/MyDrive/df_games.pkl"
# salvando os dados no Google Drive - 'wb' = write binary
with open(caminho_do_arquivo, 'wb') as file:
pickle.dump(df_games, file)E, para buscar os dados de volta:
# note que agora é 'rb' e não 'wb' - 'rb' = read binary
with open(caminho_do_arquivo, 'rb') as file:
df_games = pickle.load(file)[Opcional] — Tratando o arquivo
Não é uma etapa do Web Scraping e isso não será realizado aqui, mas uma boa coisa a ser feita é tratar os dados antes de disponibilizá-los, removendo linhas duplicadas, tratando valores vazios, etc. Isso ajudará as futuras pessoas que utilizarão os dados, facilitando o trabalho. Recomendo utilizar bibliotecas como NumPy e Pandas para realizar os tratamentos.
As possibilidades com o Web Scraping são diversas, sendo uma técnica muito poderosa para obtenção de dados e sendo muito utilizada em diversas áreas! Apenas tenha cuidado com o uso legal da técnica, usando-a de forma ética e respeitando os termos de serviço do site. Para mais informações sobre segurança e ética em ciência de dados, recomendo a leitura de um outro artigo aqui do Techblog:

Obrigado por ler e espero que tenha gostado! 👋
Até a próxima! 🚀
Dataset gerado e código completo do Web Scraping:



Web Scraping - Collecting 60k lines of video game data
A inspiração para realizar Web Scraping e construir o dataset veio de um projeto similar, também postado no Kaggle:

Fontes e outros materiais relevantes




 Oscar Valente Cardoso
Oscar Valente Cardoso






Comments ()