
A practical and gentle introduction to web scraping with Puppeteer
If you are wondering what that is, Puppeteer is a Google-maintained Node library that provides an API over the DevTools protocol, offering us the ability to take control over Chrome or Chromium and do very nice automation and scraping related things.

If you are wondering what that is, Puppeteer is a Google-maintained Node library that provides an API over the DevTools protocol, offering us the ability to take control over Chrome or Chromium and do very nice automation and scraping related things.
It’s very resourceful, widely used, and probably what you should take a look today if you need to develop something of the like. It’s use even extends to performing e2e tests with front-end web frameworks such as Angular, it’s a very powerful tool.
In this article we aim to show some of the essential Puppeteer operations along with a very simple example of extracting Google’s first page results for a keyword, as a way of wrapping things up.
Oh, and a full and working repository example with all the code shown in this post can be found here if you need!
TL;DR
- We’ll learn how to make Puppeteer’s basic configuration
- Also how to access Google’s website and scrap the results page
- All of this getting into detail about a couple of commonly used API functions
First step, launching a Browser instance
Before we can attempt to do anything, we need to launch a Browser instance as a matter to actually access a specific website. As the name suggests, we are actually going to launch a full-fledged Chromium browser (or not, we can run in headless mode), capable of opening multiple tabs and as feature-rich as the browser you may be using right now.
Launching a Browser can be simple as typing await puppeteer.launch(), but we should be aware that there is a huge amount of launching options available, whose use depends on your needs. Since we will be using Docker in the example, some additional tinkering is done here so we can run it inside a container without problems, but still serves as a good example:
async function initializePuppeteer() {
const launchArgs = [
// Required for Docker version of Puppeteer
"--no-sandbox",
"--disable-setuid-sandbox",
// Disable GPU
"--disable-gpu",
// This will write shared memory files into /tmp instead of /dev/shm,
// because Docker’s default for /dev/shm is 64MB
"--disable-dev-shm-usage"
];
return puppeteer.launch({
executablePath: "/usr/bin/chromium-browser",
args: launchArgs,
defaultViewport: {
width: 1024,
height: 768
}
});
}Launching a browser instance
Working with tabs
Since we have already initialized our Browser, we need to create tabs (or pages) to be able to access our very first website. Using the function we defined above, we can simply do something of the like:
const browser = await initializePuppeteer()
const page = await browser.newPage()
await scrapSomeSite(page)Creating a tab and doing something with it
Accessing a website
Now that we have a proper page opened, we can manage to access a website and do something nice. By default, the newly created page always open blank so we must manually navigate to somewhere specific. Again, a very simple operation:
await page.goto("https://www.google.com/?gl=us&hl=en", {
timeout: 30000,
waitUntil: ["load"],
});Navigation to a specific URL
There are a couple of options in this operation that requires extra attention and can heavily impact your implementation if misused:
timeout: while the default is 30s, if we are dealing with a somewhat slow website or even running behind proxies, we need to set a proper value to avoid undesired execution errors.waitUntil: this guy is really important as different sites have completely different behaviors. It defines the page events that are going to be waited before considering that the page actually loaded, not waiting for the right events can break your scraping code. We can use one or all of them, defaulting toload. You can find all the available options here.
Page shenanigans
Google’s first page
So, we finally opened a web page! That’s nice. We now have arrived at the actually fun part.
Let’s follow the idea of scraping Google’s first result page, shall we? Since we have already navigated to the main page we need to do two different things:
- Fill the form field with a keyword
- Press the search button
Before we can interact with any element inside a page, we need to find it by code first, so then we can replicate all the necessary steps to accomplish our goals. This is a little detective work, and it may take some time to figure out.
We are using the US Google page so we all see the same page, the link is in the code example above. If we take a look at Google’s HTML code you’ll see that a lot of element properties are properly obfuscated with different hashes that change over time, so we have lesser options to always get the same element we desire.
But, lucky us, if we inspect the input field, one can find easy-to-spot properties such as title="Search" on the element. If we check it with a document.querySelectorAll("[title=Search]") on the browser we’ll verify that it is a unique element for this query. One down.
We could apply the same logic to the submit button, but I’ll take a different approach here on purpose. Since everything is inside a form , and we only have one in the page, we can forcefully submit it to instantly navigate to the result screen, by simply calling a form.submit(). Two down.
And how we can “find” these elements and do these awesome operations by code? Easy-peasy:
// Filling the form
const inputField = await page.$("[title=Search]");
await inputField.type("puppeteer", { delay: 100 });
// Forces form submission
await page.$eval("form", form => form.submit());
await page.waitForNavigation({ waitUntil: ["load"] });Filling Google’s form and submitting it
So we first grab the input field by executing a page.$(selectorGoesHere) , function that actually runs document.querySelector on the browser’s context, returning the first element that matches our selector. Being that said you have to make sure that you’re fetching the right element with a correct and unique selector, otherwise things may not go the way they should. On a side note, to fetch all the elements that match a specific selector, you may want to run a page.$$(selectorGoesHere) , that runs a document.querySelectorAll inside the browser’s context.
As for actually typing the keyword into the element, we can simply use the page.type function with the content we want to search for. Keep in mind that, depending on the website, you may want to add a typing delay (as we did in the example) to simulate a human-like behavior. Not adding a delay may lead to weird things like input drop downs not showing or a plethora of different strange things that we don’t really want to face.
Want to check if we filled everything correctly? Taking a screenshot and the page’s full HTML for inspecting is also very easy:
await page.screenshot({
path: "./firstpage",
fullPage: true,
type: "jpeg"
});
const html = await page.content();Taking screenshots and full-page HTML’s
To submit the form, we are introduced to a very useful function: page.$eval(selector, pageFunction) . It actually runs a document.querySelector for it’s first argument, and passes the element result as the first argument of the provided page function. This is really useful if you have to run code that needs to be inside the browser’s context to work, as our form.submit() . As the previous function we mentioned, we also have the alternate page.$$eval(selector, pageFunction) that works the same way but differs by running a document.querySelectorAll for the selector provided instead.
As forcing the form submission causes a page navigation, we need to be explicit in what conditions we should wait for it before we continue with the scraping process. In this case, waiting until the navigated page launches a load event is sufficient.
The result page
With the result page loaded we can finally extract some data from it! We are looking only for the textual results, so we need to scope them down first.
If we take a very careful look, the entire results container can be found with the [id=search] > div > [data-async-context] selector. There are probably different ways to reach the same element, so that’s not a definitive answer. If you find a easier path, let me know.
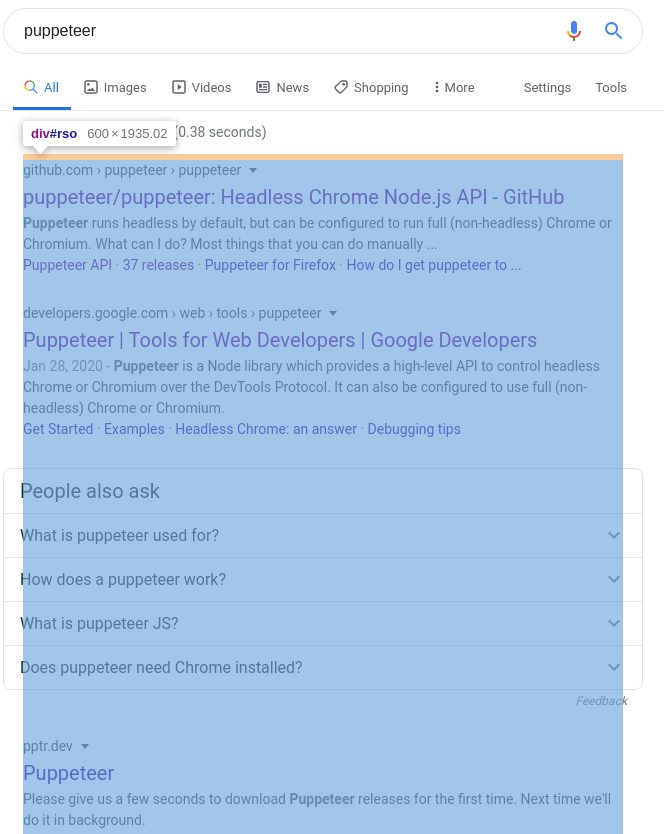
And, lucky us, every text entry here has the weird .g class! So, if we query this container element we found for every sub-element that has this specific class (yes, this is also supported) we can have direct access to all the results! And we can do all that with stuff we already mentioned:
const rawResults = await page.$("[id=search] > div > [data-async-context]");
const filteredResults = await rawResults.$$eval(".g", results =>
Array.from(results)
.map(r => r.innerText)
.filter(r => r !== "")
);
console.log(filteredResults)Extracting text data from Google’s result page
So we use the page.$ function to take a hold on that beautiful container we just saw, so then a .$$eval function can be used on this container to fetch all the sub-elements that have the .g class, applying a custom function for these entries. As for the function, we just retrieved the innerText for every element and removed the empty strings on the end, to tidy up our results.
One thing that should not be overlooked here is that we had to use Array.from() on the returning results so we could actually make use of functions like map , filter and reduce . The returning element from a .$$eval call is a NodeList , not an Array, and it does not offer support for some of the functions that we otherwise would find on the last.
If we check on the filtered results, we’ll find something of the like:
[
'\n' +
'puppeteer/puppeteer: Headless Chrome Node.js API - GitHub\n' +
'github.com › puppeteer › puppeteer\n' +
'Puppeteer runs headless by default, but can be configured to run full (non-headless) Chrome or Chromium. What can I do? Most things that you can do manually ...\n' +
'Puppeteer API · 37 releases · Puppeteer for Firefox · How do I get puppeteer to ...',
'\n' +
'Puppeteer | Tools for Web Developers | Google Developers\n' +
'developers.google.com › web › tools › puppeteer\n' +
'Jan 28, 2020 - Puppeteer is a Node library which provides a high-level API to control headless Chrome or Chromium over the DevTools Protocol. It can also be configured to use full (non-headless) Chrome or Chromium.\n' +
'Quick start · Examples · Headless Chrome: an answer · Debugging tips',
'People also ask\n' +
'What is puppeteer used for?\n' +
'How does a puppeteer work?\n' +
'What is puppeteer JS?\n' +
'Does puppeteer need Chrome installed?\n' +
'Feedback',
# ...
]And we have all the data we want right here! We could parse every entry here on several different ways, and create full-fledged objects for further processing, but I’ll leave this up to you.
Our objective was to get our hands into the text data, and we managed just that. Congratulations to us, we finished!
Wrapping things up
Our scope here was to present Puppeteer itself along with a series of operations that could be considered basic for almost every web scraping context. This is most probably a mere start for more complex and deeper operations one may find during a page’s scraping process.
We barely managed to scratch the surface of Puppeteer’s extensive API, one that you should really consider taking a serious look into. It’s pretty well-written and loaded with easy-to-understand examples for almost everything.
This is just the first of a series of posts regarding Web scraping with Puppeteer that will (probably) come to fruition in the future. Stay tuned!


Comments ()