
Elefantes nunca esquecem, mas humanos sim: automatizando o histórico do seu projeto por meio de commitizen e semantic-release.
Existe um padrão muito belo, conhecido e admirado por todos, de nome Semantic Versioning. Assim o dizem que esse padrão visa trazer um significado ao versionamento de seu projeto, da mesma maneira que o subtexto em uma boa história procura trazer significado oculto nas entrelinhas.

Atualmente, no desenvolvimento de software, mesmo se tratando do escopo único de uma única linguagem, uma única implementação pode ser aplicada de muitas maneiras. Quando se trata de projetos de grande escopo, sempre há discrepâncias na maneira como cada um costuma desenvolver. Do nível mais básico, da maneira como descreve seu trabalho em seu commit até ao nível mais técnico, como padrões de codificação.
A variável há de ter um minúsculo em seu nome e um capital em seu restante!
Suma com essa var daqui e usa um const, meu consagrado!
Indenta essa bagaça desse código, não é code-golf não, mano!
Assim atestam as tabuletas eslint e prettier no projeto, gritando com os desenvolvedores por meio de listras vermelhas e alaranjadas no rodapé do seu código.
Ilustração de como era a programação antes da genêse do eslint, circa 1743
E assim que deve ser. Cabe muito mais reforçar essas coisas por meio da IDE do próprio desenvolvedor do que por documentos externos. É muito mais intuitivo e prático, como também muito mais seguro. Porque o desenvolvedor pode se esquecer daquilo que leu, mas o ferramental não. Ele é constante e seguro (no sentido do processo de desenvolvimento, não estou fazendo nenhuma declaração em relação à humanidade ou algo do tipo).
E quanto à maneira como descrevemos nosso trabalho? Sim, aquele rótulo que colocamos em cada bloco de nosso trabalho, nossos queridos commits. Temos comprometimento com eles? (Perceba, leitor, a sutileza da piada, que toma em conta o sentido de commit em inglês como comprometer, bom demais).
Exemplo de padrão de commits empregado em um de meus projetos de faculdade. Observe o esmero com que os desenvolvedores descrevem seu trabalho.
Como devemos descrever e quão detalhado devemos ser? Cabe quem sabe colocar o nome do arquivo ou até mesmo quem sabe o card do JIRA? Algum tipo de rótulo para indicar o intuito dessa mudança, uma correção, um adendo? Por que está se perguntando isso, como pode alguém não ter se perguntado isso até agora?
Mesmo que saiba a resposta finja que não, por favor, preciso ter um artigo aqui você sabe.
Em verdade, muitos já se perguntaram disso e alguns até se deram ao trabalho de anotar os resultados de suas discussões (homens muito melhores do que eu) e fazer dele aquilo que chamamos de paradigma. Entre esses se encontra um dos mais detalhados, racionais e úteis, de nome Conventional Commits.
Sim, é uma documentação muito bem detalhada e formatada também. Entretanto, voltando ao ponto da formatação de código, não é uma boa ideia ter que depender de algo externo ao desenvolvedor para uma ação tão habitual. Antes, deixemos algumas abas livres para as inúmeras documentações e issues de github as quais ele já terá que passar o dia vendo. Sim, como bons preguiçosos, vamos automatizar aquilo que nos é inconveniente para que então se torne conveniente.
Para esse intuito, iremos nos voltar para uma biblioteca chamada commitizen.

Você ao fim desse artigo, escrevendo seus commits com commitizen, circa 2024
Configuração Commitizen
Assumo que esteja trabalhando em um projeto em Node a primeiro momento. Uma escolha um tanto quanto obscura, eu sei, mas tente me seguir aqui.
Para começar, como toda boa biblioteca, começamos instalando-a. Globalmente, no caso.
$ npm install commitizen -g
Podemos instalar ela diretamente no projeto e configurar na mão, caso queiramos, mas instalando ela globalmente já temos acesso a uma CLI conveniente para essa configuração. Atente ao --save-dev, isso é apenas para desenvolvimento, não é algo que deve ser levado em conta para a distribuição final (sei que é muito engraçado ficar comendo memória do navegador dos outros, mas é bom evitar).
# npm
commitizen init cz-conventional-changelog --save-dev --save-exact
# yarn
commitizen init cz-conventional-changelog --yarn --dev --exac
Este comando irá resultar na seguinte configuração em seu package.json, que irá fazer o commitizen estender do padrão conventional commits.
"devDependencies": {
"cz-conventional-changelog": "^3.3.0"
},
"config": {
"commitizen": {
"path": "./node_modules/cz-conventional-changelog"
}
}
E é isso. Por padrão, ao rodar o comando git cz (não é um comando padrão git, é dado pela biblioteca), você terá acesso ao cli do commitizen que vai indicar passo a passo a definição de um commit:
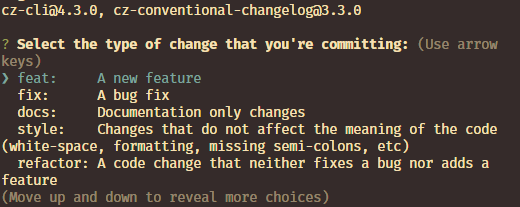
Entretanto, há um ponto aqui. Não necessariamente um problema, mas algo a se relevar. Quando se trata desse tipo de automações, é importante se lembrar do intuito de remover a dependência de ação manual do usuário em geral, como já iteramos acima.
Enquanto é possível se lembrar de sempre rodar um git cz para sempre ter acesso ao CLI, seria muito melhor configurar essa CLI de maneira que aceitasse um git commit. Por que, você se pergunta? (Ao menos assumo que pergunta, se não, finja interesse).
Simplesmente, git cz é um adendo. Não é algo que você vai ver numa cheatsheet de comandos git ou até mesmo como um alias de zsh. É um comando providenciado por uma biblioteca específica. O reflexo mecânico é digitar sempre um commit após o git ao terminar nosso trabalho.
Por mais pequenos que pareçam esses pontos, é algo importante a se relevar. Automatizações, por mais pequenas que sejam, costumam funcionar melhor quando passam por um fluxo já comum. E, se tratando de suporte ao alias de zsh, boa parte deles costumam estender de um git commit base, então podemos só usar plugins base sem ter de ficar alterando seu código.
Para cumprir com o intuito de remover esse pertinente inconveniente, agora vamos para a biblioteca com nome de raça de cachorro que usa terminologia de pesca.

Representação visual da biblioteca husky.
Husky Hooks
O husky (a biblioteca, não o cachorro) tem como intuito providenciar uma série de "anzóis" (o conceito, não o objeto) no decorrer do ciclo de vida de seu commit, como demonstrado na imagem abaixo:
Por si só, apenas provêm esses ganchos, sem nenhuma interação maior. Cabe a nós trazermos alguma ação a cada um desses ganchos. No nosso caso específico, gostaríamos de mostrar o commitizen logo antes de mostrar o resultado e fechar ele.
Para isso, vamos usar o hook prepare-commit-msg, que roda logo antes do hook de fechamento da mensagem, commit-msg.
Primeiramente, instalamos o husky no projeto como uma devDependency (mesmo ponto que na instalação do commitizen. É engraçado, eu sei, mas tente evitar).
# npm
npm install --save-dev husky
# yarn
yarn add --dev husky
Com essa dependência definida em nosso projeto, podemos então rodar o comando npx husky init que já irá criar a pasta .husky no projeto, onde vão ser guardados nossos hooks. De presente, até temos um hook já pré-configurado, que roda um comando “test” antes de sequer entrar no commit (claramente vivem em um mundo de fantasia onde desenvolvedores escrevem testes, mas isso não vem ao caso).

Podemos renomear esse hook para prepare-commit-msg e colar nele o seguinte abaixo. Atente ao renomear, porque esse arquivo em si já tem as permissões necessárias para rodar no hook. Caso crie um novo arquivo, é preciso dar a eles as devidas permissões de read/write (por meio de um comando chmod ou algo semelhante).
#!/bin/sh # Definição de namespace e sintaxe, só pra deixar o código formatado na IDE
. "$(dirname "$0")/_/husky.sh"
if ! git rev-parse -q --no-revs --verify MERGE_HEAD # Certifica de que GUI não vai aparecer em caso de merge commit
then
exec < /dev/tty && yarn cz --hook || true # Executa o comando cz com a flag indicando a execução dentro de um hook
fi
exit 0
Agora, ao rodar git commit (ou usando o alias gc em meu caso), a CLI vai ser mostrada automaticamente:
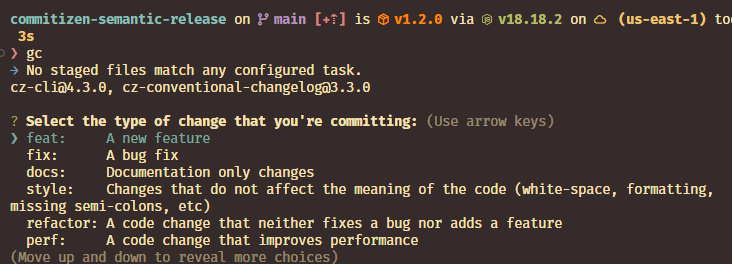
Com isso, já será reforçado de maneira automática e intuitiva um padrão de commits legível para o seu projeto. E não pense você que ele vai servir apenas para teu log ficar mais bonito não. Com essa automatização, podemos elencar uma a mais.
Semantic Release
Existe um padrão muito belo, conhecido e admirado por todos, de nome Semantic Versioning. Assim o dizem que esse padrão, por meio de várias guidelines, visa trazer um significado ao versionamento de seu projeto, da mesma maneira que o subtexto em uma boa história procura trazer significado oculto nas entrelinhas. Como é linda a teoria, morada da perfeição. Uma pena que isso não seja a realidade.
Na prática, muitos dos seus padrões acabam sendo esquecidos e nós vemos com projetos onde só sobe minor version para tudo que não seja feature (1.0.42) ou se sobe a versão major quando se julga que algo é "grande o bastante" para tal coisa e não quando esse se trata propriamente dito de uma breaking change (projetos que chegam na versão estável de 20.0.0 em 2 meses, por exemplo, antes mesmo de sequer subir para produção). Muito disso, como no quesito anterior, se dá simplesmente pelo fator humano envolvido.
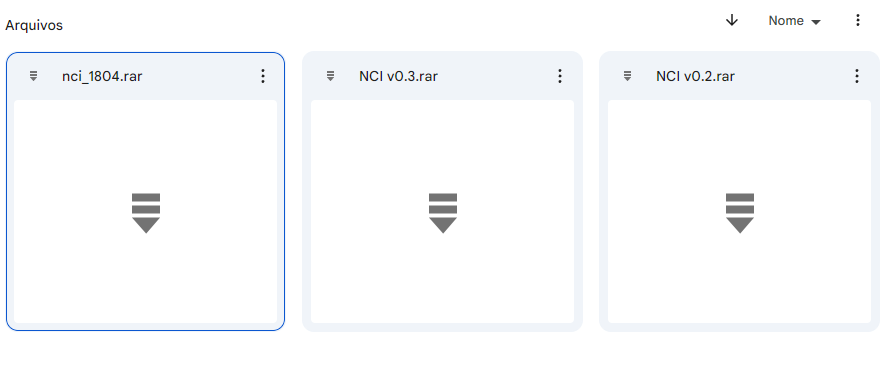
Exemplo de controle de versionamento (na verdade, a falta dele) empregado em um de meus projetos de faculdade. Observe a falta de padronização até mesmo no nome de um arquivo para outro e a falta de lógica da versão 1804, que não sei dizer agora se era para ser uma versão ou uma data.
Releases são geradas de qualquer maneira e o controle do que sobe em cada uma delas, principalmente em projetos de grande escopo, se torna inexistente. Bugs ocorrem e é preciso passar por três canais diferentes (ou pasme leitor, até mais) para entender o que diachos subiu para que isso ocorresse. E no caso de múltiplos times envolvidos, existem várias fontes de verdade para se entender uma única subida.
Mas, estendendo da nossa automatização anterior, podemos tomar essa padronização de commits em nosso repo como a nova fonte de verdade. Finalmente, a feature será uma feature e um fix será um fix, como idealizado por John Internet, criador da internet (Quem sabe esse não seja seu nome e sequer tenha idealizado isso, mas há a possibilidade!).
Para isso, iremos utilizar uma biblioteca chamada semantic-release, que irá fazer todo o trabalho de gerar nossa versão e até mesmo mais! Sim, algo digno de uma exclamação no fim da frase, leitor!

John Internet lendo esse artigo (quem sabe não seja ele e ele sequer leia esse artigo, mas há a possibilidade!).
E, como toda boa biblioteca node, precisamos instalá-la:
# npm
npm install --save-dev semantic-release
## yarn
yarn add --dev semantic-release
Como sempre, assumo muitas coisas de você, leitor. Não leve para o lado pessoal, é apenas a natureza desse artigo. No caso, assumo que está usando o github como host de seu repo e que, ao menos por momento, possui uma única branch (fiquei tentado a escrever galho) onde fica seu código "estável", de nome main.
Para esse seguinte caso, em nosso package.json, podemos configurar o semantic-release da seguinte maneira:
"release": {
"branches": ["main"],
"plugins": [
"@semantic-release/changelog",
"@semantic-release/commit-analyzer",
"@semantic-release/release-notes-generator",
[
"@semantic-release/npm",
{
"npmPublish": false
}
],
[
"@semantic-release/git", {
"assets": [
"package.json",
"CHANGELOG.md"
],
"message": "chore(release): ${nextRelease.version} [skip_ci]\n\n${nextRelease.notes}"
}
]
]
}
Vou passar ponto por ponto da nossa configuração.
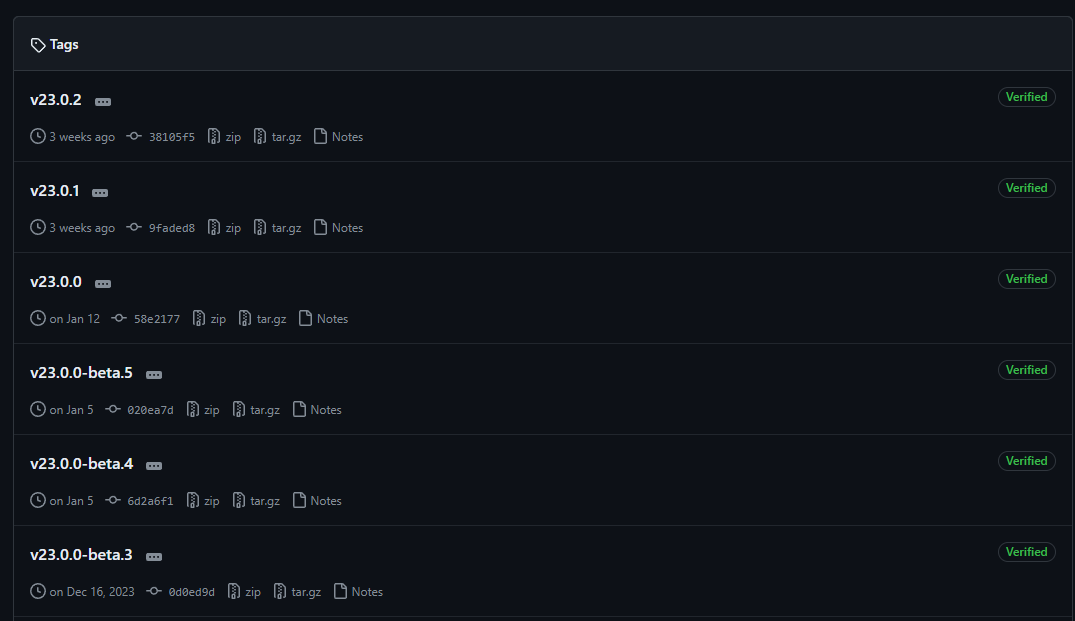
O primeiro parâmetro, branches, é um array que define as branches válidas para um semantic-release. Isso é necessário de maneira que ele entende quando gerar uma nova tag de versão. Em casos de multiplas branches, podem até ser definidos prefixos para essa tag. Um bom exemplo disso é o repo do próprio semantic-release:
Então, definimos os plugins que iremos utilizar em nossa release. Por padrão, junto da instalação base são definidos os seguintes plugins:
- @semantic-release/commit-analyzer: Analisa os commits da branch com base no padrão conventional commit
- @semantic-release/release-notes-generator: Gera um changelog com base no mesmo critério acima.
- @semantic-release/npm: Calcula e altera a versão do projeto e publica o pacote npm (opcional).
- @semantic-release/github: Integração de semantic-release-bot para as alterações acima para github
Além desses, existe uma gama de plugins oficiais e da comunidade, seja de suporte para outros provedores gits como gitlab, como também até mesmo um bot para notificar em canais slack. Para nosso fim, iremos apenas utilizar esses plugins bases, mas dê uma fuçada nessa listagem que pode achar algo interessante para o nicho de seu projeto.
Voltando à nossa configuração, não é necessário nada a mais senão a definição no caso dos três primeiros plugins. O único que possui alguma configuração é o plugin do github, onde definimos por meio do array assets o caminho do nosso package.json e CHANGELOG.md no projeto e o padrão para a mensagem de commit do bot.
Com isso, fechamos nossa configuração. Vendo que o semantic-release é uma biblioteca basicamente voltada para o processo de gerar um release em um CI, não há muito que validar localmente senão rodar um dry-run por meio do comando yarn release para validar se nossa configuração está rodando corretamente.
Da mesma maneira que a Ana Maria Braga ia até um ponto da receita para então tirar o prato pronto do nada, apresento o meu prato pronto aqui! No seguinte projeto, tenho configurado uma action básica que, em suma, apenas roda o release e define a variável utilizada por seu plugin. Sim, apenas isso. Não é preciso mais nada.
Eu gerando as releases de meu projeto. Entendeu? Estou dormindo, porque não preciso fazer nada para gerar elas! Elas se gerão sozinhas! Logo, não preciso estar acordado.

Com isso, são gerados releases e tags com base em cada commit na branch main, sempre atentando ao histórico do que já subiu. E também um changelog completo e bem estruturado, delineando a subida de cada versão em um só lugar, com o hash de cada commit. Agora é muito mais fácil de encontrar o meliante que quebrou o ambiente de produção, é como se você tivesse seu dossiê da Interpol. Também atente para o segundo contribuidor principal do repo, que efetua todas essas mudanças.
Tudo isso é uma dádiva para um projeto de grande escopo. A fonte de verdade do que subiu em seu repo é o próprio repo em si. E para fins mais minuciosos, um git log bem legível, com clara definição do intuito de cada subida à primeira vista.
Obviamente, esse é um exemplo bem básico. Há muito mais o que automatizar num projeto e quem sabe até mesmo coisas que julga mais importantes. Entretanto, isso é o tipo de mudança que se mostra seu valor no longo prazo. Também é simples o bastante para não haver nenhum custo monetário ou mental de sua parte. Então, por que não?
Veja isso mais como um ponto de partida. O final é você que define.
Quão poético, não é mesmo? Marejam meus olhos de emoção ao escrever essas palavras. Por que você vê, leitor, um dia assim exclamei:

Exclamação que foi correspondida com um exímio conselho:

E hoje, meu sonho se cumpriu. E virou um artigo. Olhe só. Quem sabe no futuro também automatize o processo de escrever um artigo. E quem sabe até mesmo trabalhar. Sim, escrever o código, marcar o ponto, encher o saco dos meus colegas nos chats de time com piadas e referências esdrúxulas.
Um dia há de se cumprir também todos esses sonhos, do mesmo modo que este se cumpriu. No fim de tudo, o intuito desse artigo é incentivar os sonhadores.
...
Na verdade, o intuito é configurar o commitizen e o semantic-release em um projeto node. Só estou enrolando um pouco aqui para ver se consigo deixar o número de palavras desse artigo em um número par para satisfazer meu TOC. Tchau, tchau!

Comments ()