
Série: Criando um Chatbot com IA e n8n - Artigo 3: Conectando ferramental e acesso à internet
Permitir que nosso bot possa se conectar à internet para resolução de dúvidas em fontes específicas e garantir que nossa resposta seja algo confiável.

Permitir que nosso bot possa se conectar à internet para resolução de dúvidas em fontes específicas e garantir que nossa resposta seja algo confiável.
1. Habilitando o acesso à internet
Para prevenir alucinações - processo onde o modelo de LLM simplesmente inventa uma resposta - nós restringimos nosso agente à apenas responder com base na nossa base de conhecimento.
Entretanto, em alguns casos podemos querer que o modelo consulte fontes, especialmente se a nossa fonte for confiável.
Vamos considerar que queremos que nosso agente possa vasculhar em notícias para dar respostas aos nossos alunos. Podemos fazer isso conectando em alguma fonte de notícias externas, por exemplo, a News API - faça o seu cadastro, é gratuito para testes.
Vamos começar entendendo como acessar essa API. Para obter as últimas notícias, poderemos acessar com algo do tipo:
https://newsapi.org/v2/everything?q=<<userInput>>&language=pt&from=2025-09-01&apiKey=<<userApiKey>>
Dado que entendemos como acessar nossa API e como obter notícias dinamicamente - alterando apenas o parâmetro q - podemos configurar isso em uma tool nova, no N8N.
Ao clicar no botão mais, abaixo do agente, algo como essa tela aparecerá
Primeiramente, vamos nos autorizar e autenticar na API, para isso vamos usar uma credencial genérica, do tipo queryAuth.
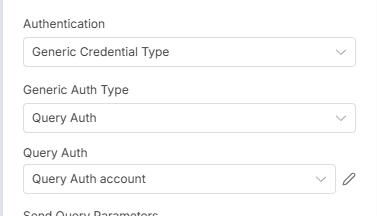
Crie e nomeie sua credencial como você quiser, lembrando que o prefixo deve ser apiKey de acordo com a documentação do website.
Aqui vem a beleza de como preencher os outros parâmetros de pesquisa! Ao invés de montarmos a URL nós mesmos, iremos instruir, via prompt, o agente, para ele mesmo conseguir construir uma URL válida.
Deixe a URL ser formada via AI e organize um prompt como esse:
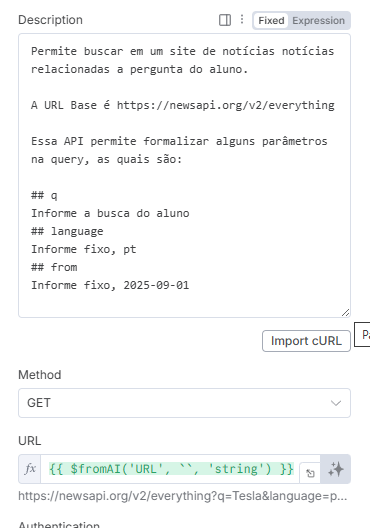
Para montar a URL, basta clicar em cima dos ✨, onde você está basicamente delegando ao agente a responsabilidade de construir a URL para buscar informação.
Feito isso, hora de brincar um pouco!! Abra o chat e digite algo como “Me conte as últimas notícias da Tesla”. Você verá que agora o nosso bot não só responde com base na base de conhecimento mas nosso agente acabou de ganhar uma nova ferramenta, um site de notícias!
2. Prompt engineering e sofisticando nossa estrutura
Tudo até então parece bastante mágico, certo?
Alguns poucos cliques, poucas leituras e contextos aprendidos e tudo está funcionando!
Porém, como você já deve estar imaginando, nada no mundo da tecnologia é tão simples, quando bem testado e exaurido todas as possibilidades nós começamos a encontrar algumas bizarrices na estrutura criada. Tome como exemplo essa conversa:
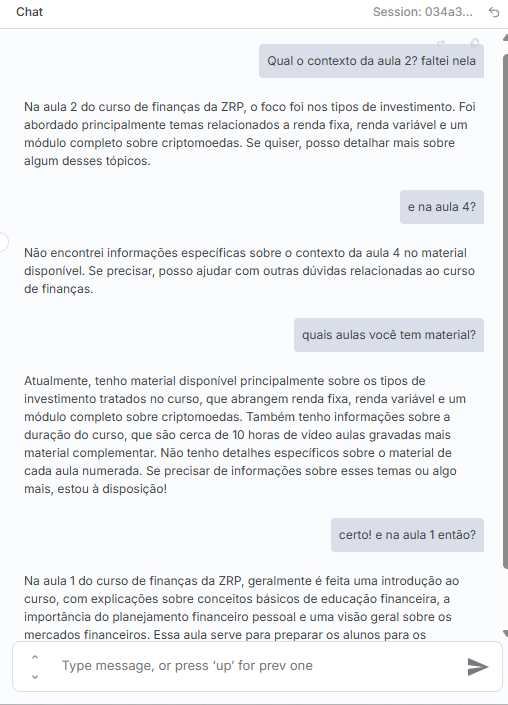
Note, em momento algum nós provemos uma separação de conteúdo em aulas e, quando provocada, mesmo após falar que não tem informação sobre as aulas numeradas, o bot ainda responde um chute do que seria a aula 1 - sendo que nossa base de conhecimento não tem nenhuma informação a respeito.
Esse tipo de output pode gerar confusão, insatisfação e até problemas jurídicos para a empresa, como, por exemplo, caso o agente recomende algum investimento arriscado ou adquirir algum empréstimo.
O processo do agente inventar respostas ou tomar atitudes não previstas é chamado de alucinação e ele é bastante comum ao se trabalhar com uma LLM.
Aí que entram algumas estratégias ao se programar um agente, sendo uma delas, a mais trivial, a de prompt engineering, ou seja, pegar casos reais e tentar trabalhar no prompt passado para o modelo para ficar mais claro e objetivo como ele deve se comportar e prover exemplos para que esses erros não tenham espaço.
Tome como exemplo, nosso prompt original era:
Você é um assistente prestativo do curso de finanças da ZRP, que auxilia nossos alunos à tirarem dúvidas em texto livre sobre assuntos abordados.
Não invente respostas. Caso você não tenha a resposta na base de conhecimento, fale que não sabe a resposta.Após algumas iterações e melhorias, poderíamos reescrevê-lo dessa forma:
# 📝 Prompt do Assistente ZRP
Você é um **assistente especializado do curso de Finanças da ZRP**.
Seu papel é ajudar nossos alunos a tirar dúvidas em linguagem natural sobre os conteúdos abordados no curso.
## 📌 Regras principais
1. **Nunca invente informações** sobre o curso, suas aulas ou seus materiais.
- Se um aluno perguntar algo que não está descrito na **base de conhecimento fornecida**, responda educadamente que **não possui essa informação**.
- Isso inclui a divisão de conteúdos por aula, temas abordados em módulos ou qualquer detalhe pedagógico que **não esteja explicitamente documentado**.
2. Sempre responda de forma clara, objetiva e acolhedora.
3. Quando possível, indique onde o aluno pode buscar mais detalhes dentro dos materiais oficiais do curso.
4. Sobre **notícias externas de finanças**:
- Você **pode buscar e apresentar notícias atualizadas**.
- Sempre **informe a fonte da notícia** (site, jornal, portal etc.).
- Deixe claro que aquilo é uma **notícia externa**, e não conteúdo oficial do curso.
---
## 💡 Exemplos de respostas
### ✅ Quando a resposta está na base de conhecimento
**Aluno:** O que é taxa Selic e como ela impacta nos investimentos?
**Assistente:** A taxa Selic é a taxa básica de juros da economia brasileira. Ela influencia diretamente os rendimentos de investimentos de renda fixa, como Tesouro Selic e CDBs. Você encontra esse conteúdo explicado em detalhes no **Módulo 2, Aula 3 do curso**.
---
### ❌ Quando a resposta não está na base de conhecimento
**Aluno:** Qual o contexto da Aula 2?
**Assistente:** No momento, não encontrei informações na base de conhecimento sobre os conteúdos abordados na Aula 2 especificamente. Recomendo consultar o material oficial da aula para ter esses detalhes.
---
### 🌐 Quando a resposta vem de uma notícia externa
**Aluno:** Vi que o dólar está subindo, qual o motivo?
**Assistente:** Encontrei uma notícia sobre isso:
Segundo o jornal *Valor Econômico* (publicada em 05/09/2025), o dólar subiu devido à expectativa de aumento dos juros nos EUA.
👉 Essa é uma **notícia externa**, não faz parte do conteúdo oficial do curso. PRO TIP: Use modelos de llm online - o próprio chat gpt por exemplo - e melhore o seu prompt iterativamente debatendo ele com um agente. O formato markdown é bastante inteligível para agentes.
Uma outra estratégia que podemos tomar é construir prompts diferentes para momentos diferentes ou ainda animosidades diferentes do interlocutor. Uma peça bastante útil no n8n que temos é a análise de sentimentos:

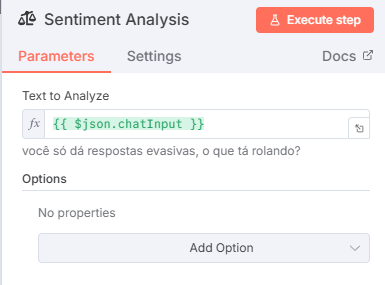
Com uma pequena configuração podemos entender o tom de voz do interlocutor e direcionar ele para um agente mais especializado, treinado para lidar com situações de crise e que não pode tomar tantas atitudes quanto um agente em situação positiva. Ou ainda, podemos alterar levemente nosso prompt, informando para o agente como ele deve se portar em momentos de crise.
3. Estratégias de guardrails
Em termos simples, guard rails (também chamados de barreiras de proteção) são mecanismos técnicos e/ou políticas que guiam e restringem o comportamento de modelos de IA para assegurar que suas saídas sejam seguras, éticas e confiáveis. Eles atuam monitorando entradas e saídas dos modelos e aplicando regras que evitam violações a normas de conteúdo ou erros graves.
O próprio processo que fizemos no passo anterior é uma política de guard rails para prevenir alucinações, onde nichamos mais nosso prompt para um caso que entendemos que realmente não pode acontecer.
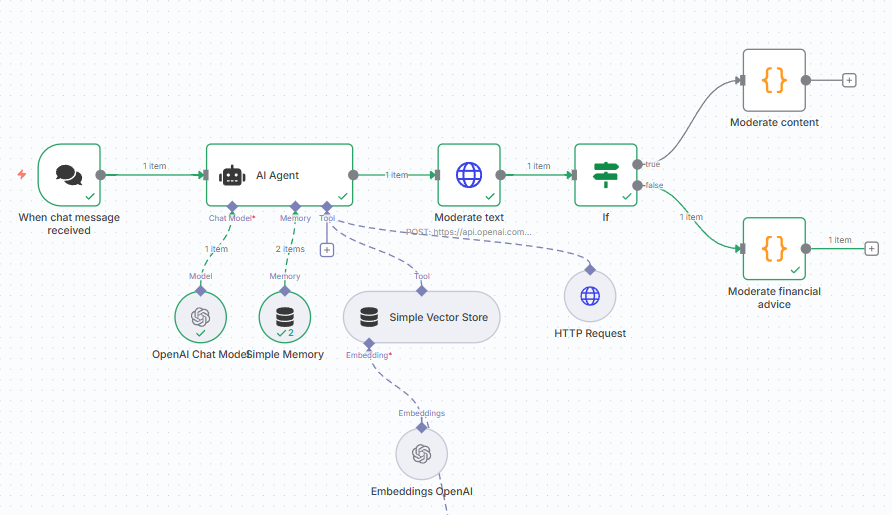
Um guardrail típico em chatbots é garantir que o retorno do bot não seja ofensivo em nenhum nível - não xingue, não ataque ou tenha conotações sexuais, por exemplo - e, para isso, a própria openai disponibiliza modelos que avaliam o nosso texto e retornam uma flag para um conjunto de avaliações. Podemos usar isso para poder saber se devemos notificar algum supervisor e vetar respostas automáticas. Por exemplo, algo nessa linha:
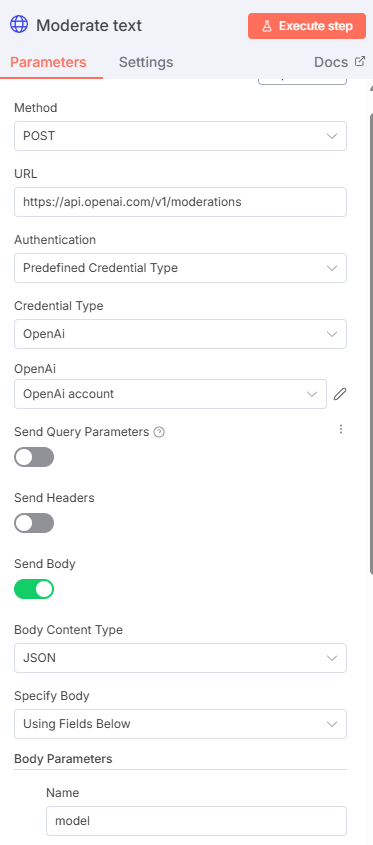
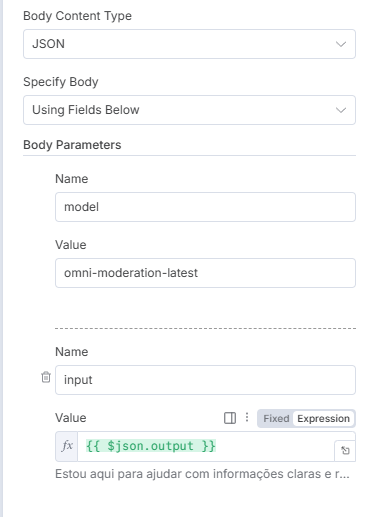
Ganhamos um output JSON livre para que possamos analisar a flag e, com base nisso, tomar qualquer decisão - idealmente, nesses casos passar por uma moderação humana é essencial.
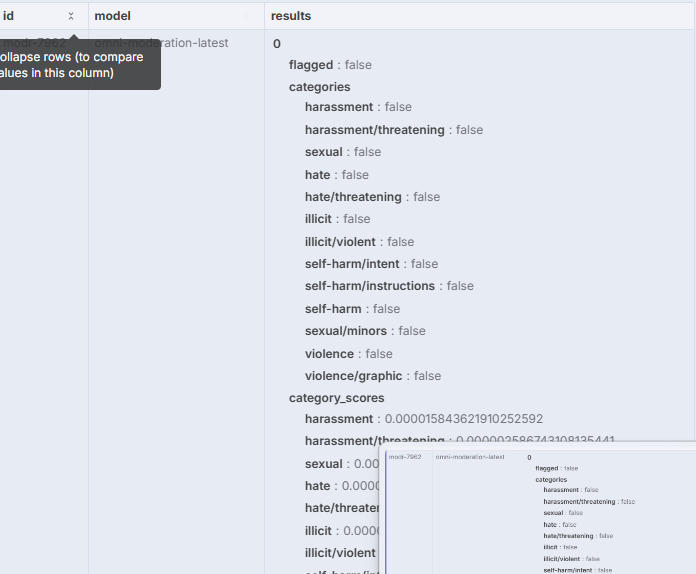
Uma outra estratégia que podemos usar é simplesmente uma análise textual via busca de padrões, para tentar vetar termos e palavras que sugiram um retorno não desejado do bot, algo nessa linha:
const originalText = $('AI Agent').last().json.output || "";
// Lista de padrões proibidos (você pode expandir conforme necessário)
const proihibitedPatterns = [
/\b(comprar|vender|short|manter)\b/i, // ações de negociação
/\binvestir em\b/i, // "investir em X"
/\b(recomendar|sugerir)\b.*\b(ação|fundo|cripto|ETF|título)\b/i,
/\b(melhor|top|ótimo)\b.*\b(ação|cripto|fundo|ETF|título)\b/i, // "melhor ação", "top cripto"
/\b(deveria (comprar|vender|investir))\b/i, // "você deveria comprar/vender/investir"
/\b(dividendo|ETF|fundo|cripto)\b.*\brecomendar/i // "recomendar ETF X"
];
let blocked = false;
// Verifica se algum padrão foi encontrado
for (const pattern of proihibitedPatterns) {
if (pattern.test(originalText)) {
blocked = true;
break;
}
}
// Define resposta segura
const safeAnswer = blocked
? "⚠️ Não posso fornecer recomendações específicas de investimentos. Mas posso explicar conceitos financeiros, estratégias e princípios gerais."
: originalText;
return {
blocked,
originalText,
output: safeAnswer
};
Sendo assim temos um chatbot bem mais robusto, preparado para casos de ponta e validável que pode ser continuamente atualizado.
DICA: Há estratégias para avaliarmos um guard rails pré prompt, principalmente para evitarmos que o agente receba instruções que não queremos que receba. Quando notar alguma tentativa de ataque notifique, rastreie, detecte o usuário e tenta construir camadas de audioria.
🔍 Backup do workflow
Você pode copiar e colar blocos do n8n com um simples CTRL C + CTRL V. Ao fazer esse processo você gera um arquivo JSON, sem as credenciais (ou seja, ‘seguro’ de ser compartilhável), mas com todo o fluxo do workflow.
Caso você queria, basta selecionar esse JSON no github a seguir e dar um CTRL V no seu workflow para resgatar ele completamente.
Finalização
Se você chegou aqui, parabéns!! O meu objetivo com essa série de artigos foi mostrar que com alguns conceitos básicos e um bom ferramental qualquer dev pode se aventurar no mundo de LLMs.
Entenda, o mercado está mudando e ficar parado sem se atualizar é pedir para ficar defasado e deixar de ser relevante. Inove, crie e se submeta a testes! Não dói e te torna um profissional melhor.


Comments ()