
Série: Criando um Chatbot com IA e n8n - Artigo 2: Base de Conhecimento Simples com IA e n8n
Integrar uma base de conhecimento própria ao chatbot de forma simples, usando um arquivo JSON como FAQ, e entender conceitos iniciais como tokens e embeddings.

Série Criando um Chatbot com IA e n8n - Artigo 2.
Integrar uma base de conhecimento própria ao chatbot de forma simples, usando um arquivo JSON como FAQ, e entender conceitos iniciais como tokens e embeddings.
1. Como montar uma base de conhecimento simples em JSON
Um dos grandes desafios quando começamos a construir um chatbot é construir uma boa base de conhecimento, organizada e normalizada, para que ele tenha conhecimento para responder à pergunta.
O formato JSON é uma forma leve e estruturada de organizar conteúdo livre. Para um FAQ essa estrutura pode simbolizar uma tabela, um backend, ou qualquer outra fonte de dados estruturada.
Vamos começar com o caso de uso no qual temos que montar um agente que retira dúvidas de alunos sobre um curso de finanças. Para tal, vamos começar com algo bem simples, como:
[{
pergunta: "quais tipos de investimento falamos no curso?",
resposta: "no curso falamos sobre renda fixa, renda variável e enfatizamos um módulo completo de criptomoedas"
},
{
pergunta: "quanto tempo dura o curso?",
resposta: "o tempo de execução do curso depende do aluno, entretanto temos 10 horas de vídeo aulas gravadas mais material complementar"
},
{
pergunta: "o que é taxa CDI?",
resposta: "O CDI (Certificado de Depósito Interbancário) é um título emitido por um banco para outro banco com o objetivo de regularizar o caixa no final do dia. A taxa CDI, ou Taxa DI, é a referência para os juros dessas operações e é divulgada diariamente pela B3."
},
{
pergunta: "o que é a taxa SELIC?",
resposta: "A taxa Selic é a taxa básica de juros da economia brasileira, cujo nome é uma sigla para Sistema Especial de Liquidação e Custódia. Ela serve como referência para todas as demais taxas de juros no Brasil, influenciando tanto os rendimentos de aplicações financeiras quanto o custo de empréstimos e financiamentos"
}]⚠️ Atenção: Tente normalizar idiomas na sua base de conhecimento, evite chaves em inglês e valores em português, o vice versa.
Esse arquivo pode ficar hospedado:
- Em um servidor web (ex.: GitHub Pages, S3, servidor simples).
- Diretamente no repositório do chatbot.
- Em uma planilha exportada para CSV/JSON.
Assim, você terá uma base estática de FAQ que pode ser lida e atualizada sem grandes complexidades.
2. O que são tokens e embeddings
Antes de avançar, é importante entender dois conceitos fundamentais em IA generativa aplicada a texto:
- Tokens: nada mais são do que pedaços de texto que o modelo entende. É uma forma de você traduzir para a máquina palavras. Máquinas lidam bem com números, não textos, o processo de tokenizar um texto nada mais é do que realizar essa tradução.
Exemplo: a frase "horário de funcionamento" pode ser quebrada em tokens como ["horário", "de", "funcionamento"] que podem ser traduzidos para uma matriz de números como [3333, 23, 1111].
Cada LLM possui seu próprio dicionário de tokenização, podendo quebrar palavras, pedaços de palavras, frases inteiras e etc.Se você escolher algum outro modelo (mesmo que seja no mesmo provider de LLM), a tokenização mudará.
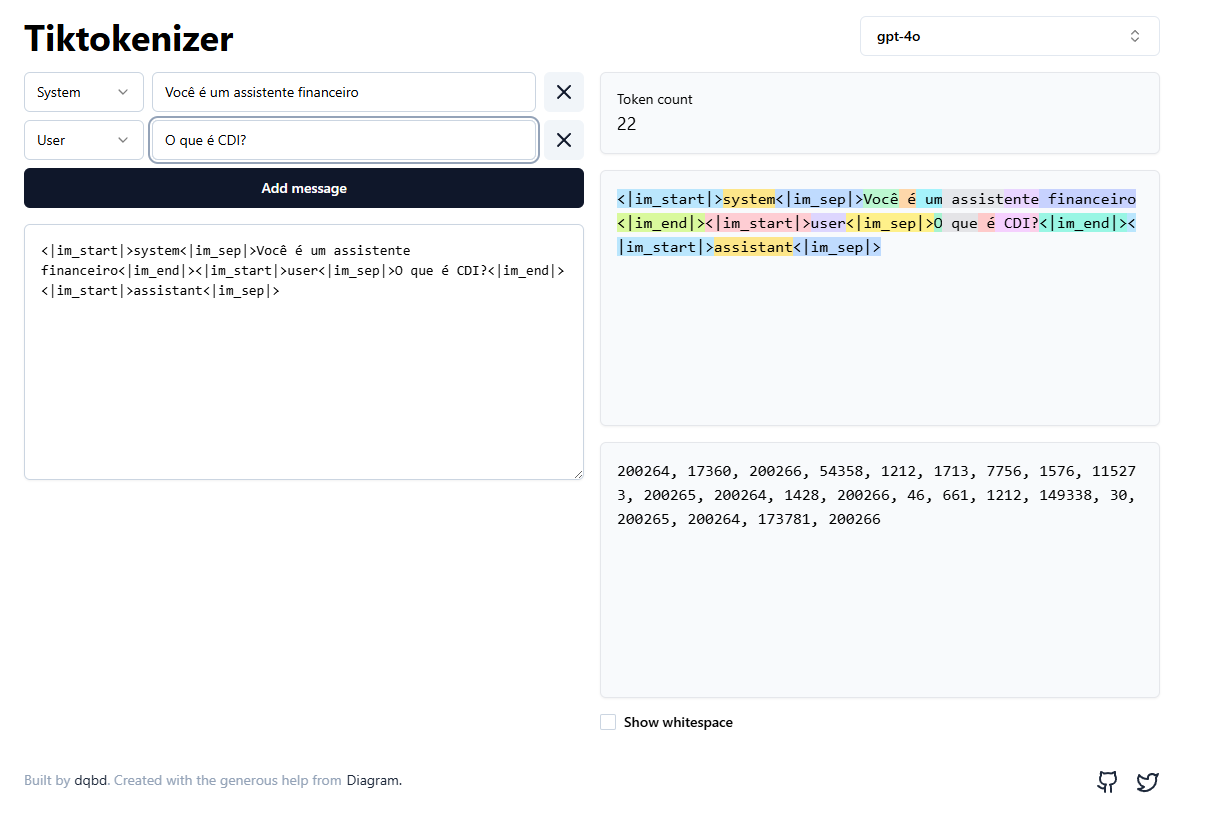
- Embeddings: são representações numéricas de textos em um espaço multidimensional. O processo de criar um embedding é basicamente posicionar os seus tokens em um gráfico multidimensional. Nesse processo transformamos frases em vetores matemáticos que capturam o “significado” do texto e posicionam-os corretamente em um espaço multidimensional.
Com isso, conseguimos medir similaridade semântica entre perguntas do usuário e sua base com estratégias de busca de distância entre vetores, ou seja, entendendo contextos de conversas e resolvendo paradigmas de comunicação.
3. Estratégias de embedding simples
Entendendo o conceito, aplicar ele em um workflow do n8n é bastante simples, isso porque já temos blocos pré prontos que nos permitem fazer todo o processo de tokenização e embedding simplesmente selecionando qual modelo irá realizar o trabalho.
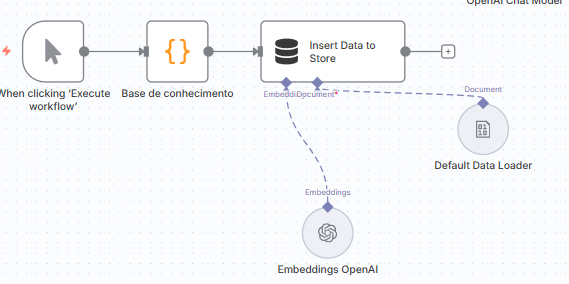
Para simplificar, faremos nossa base de conhecimento ser somente um output de um bloco de código, apenas para retornar uma lista diretamente.
Esse dado, para treinamento, poderia, por exemplo, vir de uma base do sheets (“excel online” do google) e continuamente ir aumentando o nível de conhecimento do nosso bot.
O importante ao construirmos uma base de conhecimento sólida é garantir que ela está sendo mantida e atualizada. Para tal, disponibilizar para a área de negócios uma forma fácil e acessível de manipulação desse dado é algo importante.
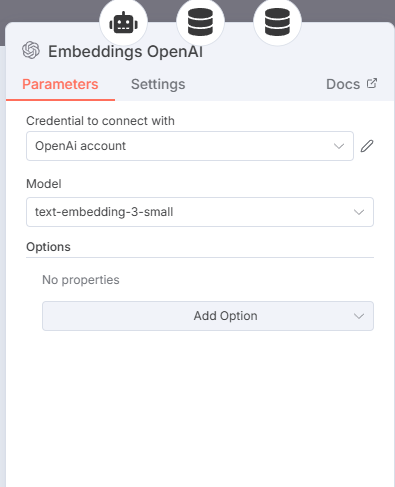
Note, conforme falamos, o processo de tokenização e embedding depende do modelo selecionado, por isso, um dos parâmetros que você deve selecionar é qual o modelo que você quer processar. Diferentes modelos possuem diferentes precificações, performance e o resultado final muito provavelmente será diferente.
4. Como fazer o chatbot responder com base em um FAQ.
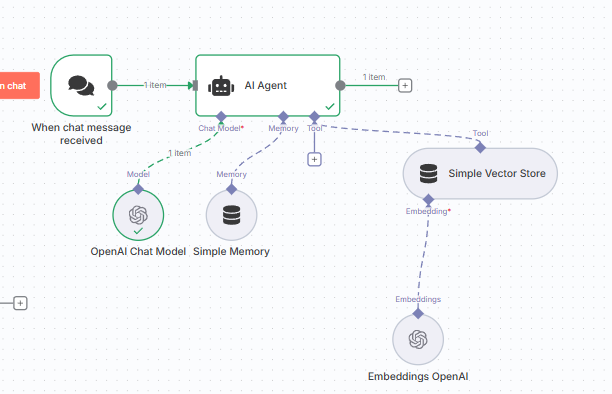
Vamos começar a construção do nosso assistente simples usando um bloco bastante poderoso do N8N, o bloco de AI Agent.
Podemos conectar em um agente os seguintes itens do n8n:
- modelo: essencial para execução e inteligência do nosso modelo
- memória: no nosso caso, algo não tão essencial, mas importante caso queiramos manter uma sessão com memória de iterações passadas - por fins de simplificação, vamos usar a memória simples do n8n
- ferramentas: as ferramentas são as ações específicas que nosso agente pode realizar. No nosso caso, a única ação que nosso agente pode realizar é consultar em uma base de dados nossa, vetorizada, o conteúdo da resposta
Para tentarmos evitar o máximo de alucinações ou respostas fora da nossa base de conhecimento temos que dar instruções claras para o nosso agente.
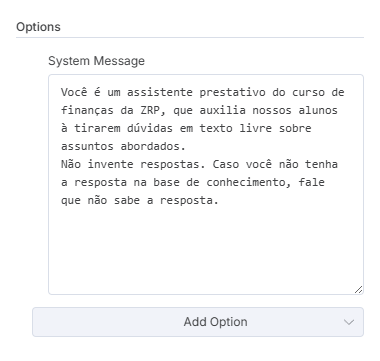
Um prompt clássico informa com quem o agente está falando, quem ele é e o que ele pode ou não pode fazer.
Como a nossa base de conhecimento está bastante organizada, a consulta do vetor pode seguir um prompt simples, algo como:
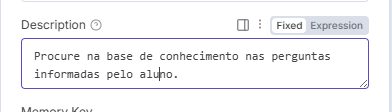
5. Hora de testar!
Feito o carregamento no banco de dados vetoriais com base na lista de JSONs, é hora de brincar!
Clique no botão de abrir chat e faça algumas perguntas para o seu recém configurado bot.
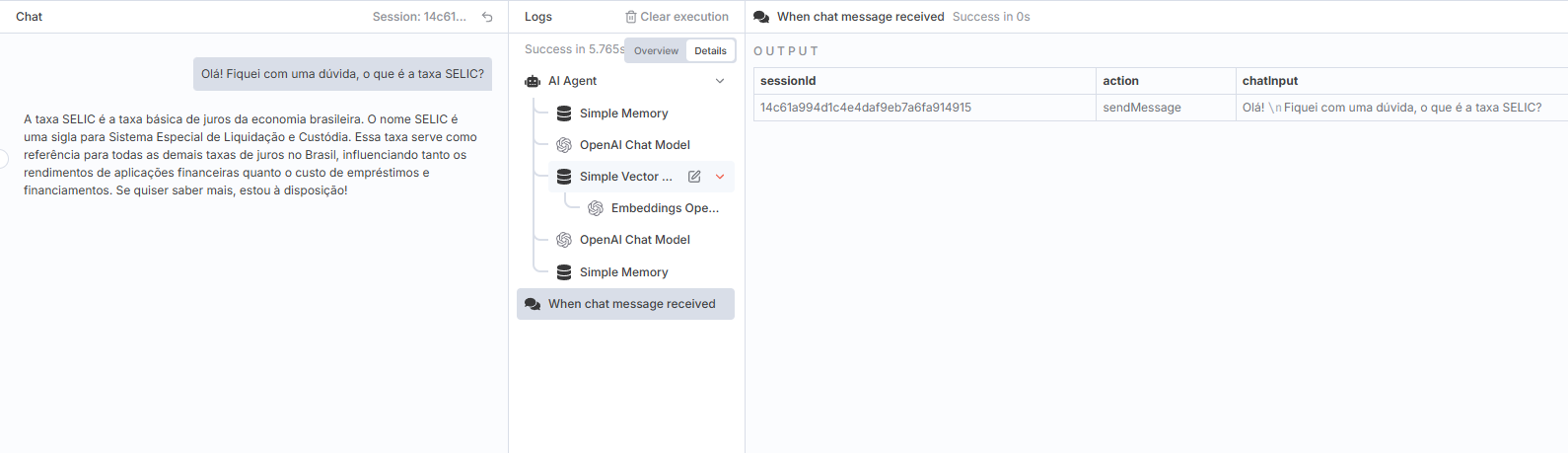
🔍 Backup do workflow
Você pode copiar e colar blocos do n8n com um simples CTRL C + CTRL V. Ao fazer esse processo você gera um arquivo JSON, sem as credenciais (ou seja, ‘seguro’ de ser compartilhável), mas com todo o fluxo do workflow.
Caso você queria, basta selecionar esse JSON a seguir e dar um CTRL V no seu workflow para resgatar ele completamente.
📦 Próximos passos da série
No próximo artigo, vamos: 👉 Entender um pouco mais como dar mais ferramentas ao nosso bot e como conectá-lo à internet.


Comments ()