
AI Engineering Infrastructure Reality Check
Your AI demo works on localhost. Now you need to deploy it for real users without it crashing everyday. Here's how to build AI infrastructure that actually survives production.

TL;DR: Your AI demo works on localhost. Now you need to deploy it for real users without it crashing everyday. Here's how to build AI infrastructure that actually survives production.
You've built an awesome AI application. It works perfectly on your computer. Users love the demo. Your PM is already planning the launch party. Then you deploy it to production.
Within 24 hours, you're getting alerts about timeouts, memory leaks, and API rate limits. Your "smart" document processor is choking on a 300 hundred page PDF someone uploaded. The system that was responding in less than 2 seconds is now taking 30 seconds or more. Your OpenAI bill for one day equals your whole development lifecycle.
Welcome to the AI infrastructure reality.
The gap between an "AI demo that works" and an "AI system that scales" is bigger than most people think. What actually works in production is far away from the demo, as we had previously talked about in the LLM Integration Playbook.
Now we need to take a deeper look, beyond the code, and into the infra-verse.
Into the Infra-Verse
Most AI engineers are awesome at building and using models, but terrible at deploying them. This is where projects have a really hard time, not in the algorithm, but in the infrastructure.
Containerization: Beyond Basic Docker
Everyone knows how to setup a basic image for an application: FROM python:3.9 and COPY . .. That's not enough for most AI systems. Specially if you're using anything more than API calls.
The problems that usually arise with a naive approach when using Docker for AI are:
- Massive image sizes (5GB+ with ML libraries)
- Slow cold starts (models take forever to load)
- Memory leaks that kill containers
- No GPU optimization if using local models
To fix that, we can use a multi-stage Dockerfile:
# Multi-stage build for GPU-optimized AI applications
FROM nvidia/cuda:11.8-devel-ubuntu20.04 as base
# Set CUDA environment variables
ENV NVIDIA_VISIBLE_DEVICES=all
ENV NVIDIA_DRIVER_CAPABILITIES=compute,utility
ENV CUDA_HOME=/usr/local/cuda
ENV PATH=${CUDA_HOME}/bin:${PATH}
ENV LD_LIBRARY_PATH=${CUDA_HOME}/lib64:${LD_LIBRARY_PATH}
# Install Python and system dependencies efficiently
RUN apt-get update && apt-get install -y \
python3.11 \
python3.11-pip \
python3.11-dev \
build-essential \
curl \
software-properties-common \
&& rm -rf /var/lib/apt/lists/*
# Create symbolic links for python3.11
RUN ln -s /usr/bin/python3.11 /usr/bin/python3 && \
ln -s /usr/bin/python3.11 /usr/bin/python
# Create non-root user for security
RUN useradd --create-home --shell /bin/bash app
USER app
WORKDIR /home/app
# Python environment setup
ENV PYTHONUNBUFFERED=1
ENV PYTHONDONTWRITEBYTECODE=1
ENV PATH="/home/app/.local/bin:$PATH"
# Install CUDA-optimized PyTorch first
RUN pip install --user --no-cache-dir \
torch torchvision torchaudio \
--index-url https://download.pytorch.org/whl/cu118
# Install dependencies in separate layer for caching
COPY requirements.txt .
RUN pip install --user --no-cache-dir -r requirements.txt
# Production stage
FROM base as production
COPY --chown=app:app . .
# Pre-download models during build (not runtime) with GPU verification
RUN python -c "
import torch
print(f'CUDA available: {torch.cuda.is_available()}')
print(f'CUDA devices: {torch.cuda.device_count()}')
import transformers
transformers.AutoTokenizer.from_pretrained('bert-base-uncased')
transformers.AutoModel.from_pretrained('bert-base-uncased')
print('Models downloaded successfully')
"
# Health check endpoint
HEALTHCHECK --interval=30s --timeout=10s --start-period=60s --retries=3 \
CMD curl -f http://localhost:8000/health || exit 1
EXPOSE 8000
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000", "--workers", "1"]Let's break this down.
First, instead of using a base Python image, use a base nvidia/cuda image, and split your build and runtime into different stages. This allows you to easily create new stages if required, and keeps your "setup" stage (what you need to do at the system level to build/run your application) separate from the "runtime" stage (what you need to execute the system using the bare minimum).
This approach splits dependency installation apart, which speeds up builds when your dependencies don't change. In practice, this means a code change rebuilds in 30 seconds instead of 5 minutes.
It's also good practice to set a new user to run as a non-root user. This prevents privilege escalation attacks to the underlying system in production, if attackers gain access to your containers.
The final step is pre-downloading models during the build phase, eliminating the "model loading delay" that kills user experience. Your containers start fast because everything is already cached.
The Production Architecture That Scales
Now that we have a ready to deploy image, let's skip what most tutorials show you: how to deploy a single container. Real AI systems need more than that.
If AI is the core of your system, you need clear separation of concerns. Input side: monitor and route traffic intelligently. Output side: cache results, queue long operations, and store models efficiently.
This leads to a proven architecture:
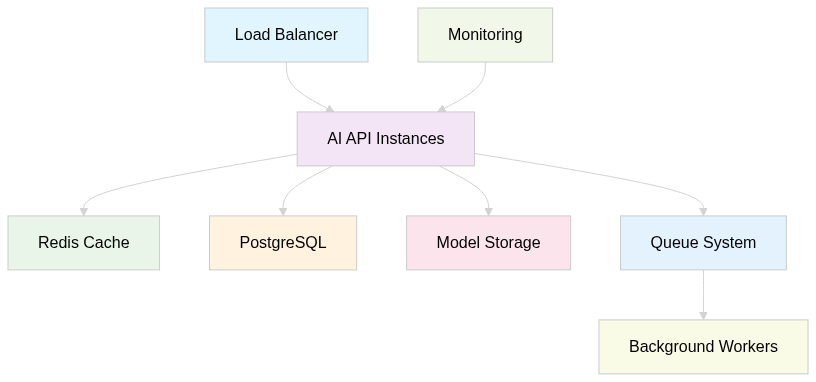
Look how your AI instances are just a small part of your architecture. They're your core, but to work at their finest, you need components that implement and manage the data flow—from user to instance, and from instance to storage (and vice-versa).
The components that matter:
- Load Balancer: Routes traffic and handles SSL termination
- Multiple API Instances: Horizontal scaling for reliability
- Redis Cache: Prevents expensive re-computations
- Queue System: Handles long-running AI tasks asynchronously
- Model Storage: Centralized model versioning and serving
- Monitoring: Alerts before things break
Monitoring That Actually Helps
On the subject of monitoring, most setups are useless for AI systems. You get alerts about CPU / GPU usage, but you don't know why your model accuracy dropped by 20%.
When talking about AI systems, we should have at least:
- Request latency by operation type (inference vs training)
- Model prediction confidence scores (detect degradation)
- API cost per request (prevent budget disasters)
- Memory usage patterns (spot memory leaks early)
- Error rates by input type (identify problematic data)
When looking at LLMs, from simple non-agentic workflows to multi-agent systems, this gets even deeper.
Traditional ML gives you clean metrics: accuracy scores, F1 scores, confusion matrices. LLMs? You get text output that could be brilliant or garbage, and distinguishing between them programmatically is hard.
The LLM monitoring challenge:
- No objective "correctness" score - How do you measure if a generated content is "good"?
- Context dependency - The same response might be perfect for one user, terrible for others
- Semantic drift - Model outputs slowly change over time in ways traditional metrics miss
- Multi-step complexity - In agent systems, failure can happen at any step in a multi-step workflow, as errors cascade in the chain
What actually works for LLM monitoring:
- Output length tracking - Sudden changes in response length often indicate issues
- Refusal rate monitoring - Track when models say "I can't help with that"
- User feedback loops - Collect thumbs up/down data, this is more valuable than technical metrics
- Semantic similarity checks - Compare outputs to known good examples
- Cost per conversation - Track spending at the user session level, not just per request
For agentic systems, add:
- Task completion rates - Did the agent actually finish what it started?
- Decision tree depth - How many steps did it take to reach a conclusion?
- Tool usage patterns - Which APIs are agents calling most often?
- Human intervention frequency - How often do agents escalate to humans?
The key insight: LLM monitoring is more about user experience than technical performance. A system with perfect uptime, or fast response times, that generates unhelpful responses is still broken.

MLOps Without the Enterprise Bloat
MLOps vendors want you to believe you need a thousand-dollar platform. You don't. You need simple, reliable workflows that internal teams understand and can execute precisely.
Model Versioning
Forget complex ML platforms. Model versioning is a lot like code versioning—a model is comprised of a training dataset, metadata, and its content. Here's what works in production:
Simple model registry approach:
- Hash-based versioning: Model version = content hash
- Metadata tracking: Store accuracy metrics, training data info
- Promotion workflow: Staging → Production with approval gates
- Rollback capability: Switch back to previous version instantly
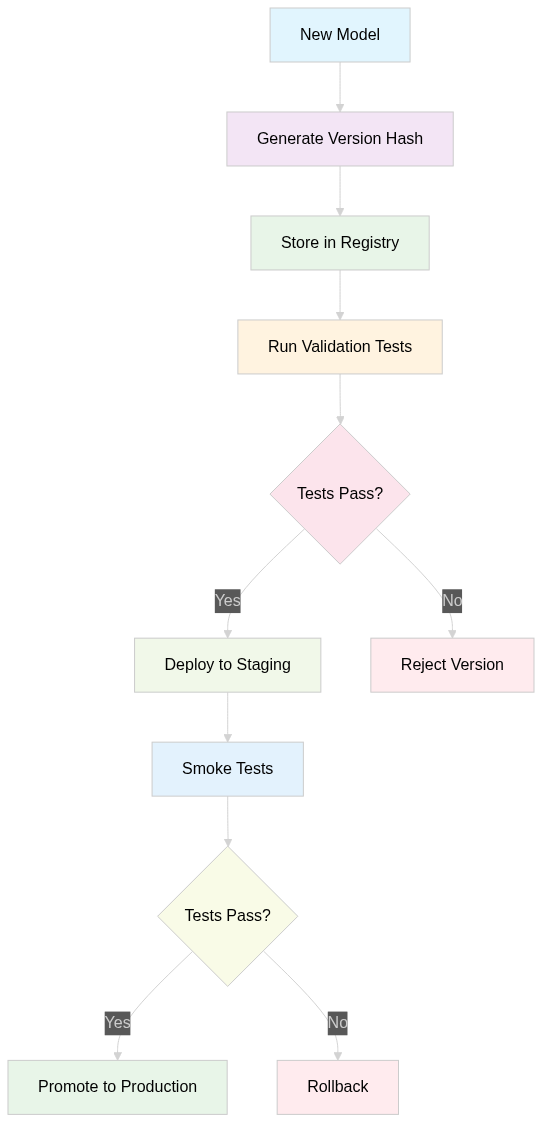
Key insight: Keep it simple. Complex MLOps platforms often become bottlenecks. A well-designed file system with proper metadata beats most enterprise solutions.
Hugging Face as a Middle Ground
For teams that need more than local file storage but want to avoid enterprise MLOps complexity, Hugging Face offers a practical alternative:
What works well with Hugging Face:
- Git-based versioning: Models are stored like code repositories with proper version history
- Built-in metadata: Model cards, training details, and performance metrics in one place
- Easy integration: Works seamlessly with transformers library and existing workflows
- Team collaboration: Share models privately within organizations without complex infrastructure
- Cost-effective: Free for public models, reasonable pricing for private repositories
When Hugging Face makes sense:
- You're using transformer-based models (BERT, GPT, etc.)
- Team needs to share and iterate on models frequently
- You want versioning without building custom infrastructure
- Compliance allows external model hosting
When to stick with local file systems:
- Strict data sovereignty requirements
- Custom model formats that don't fit Hugging Face standards
- Need for complex approval workflows
- Very large models (100GB+) where transfer costs matter
Hybrid approach: Many production teams use Hugging Face for development and experimentation, then export final models to internal systems for production deployment. This gives you the collaboration benefits without vendor lock-in for critical systems.
The key is matching your versioning complexity to your actual needs, not what MLOps vendors think you should need.
Deployment Patterns That Don't Fail
You've figured out the infrastructure and MLOps—now it's finally time to deploy. How do you deploy smoothly and unnoticed?
Blue-Green Deployments for AI Models
Instead of replacing models directly, run two identical environments and switch traffic between them:
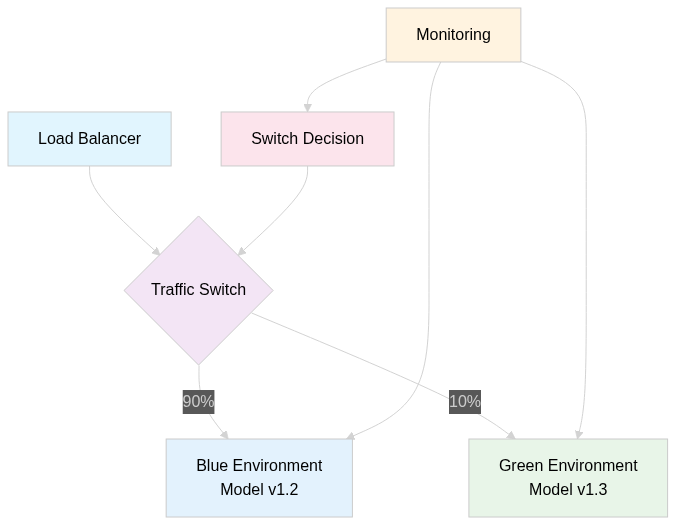
Benefits:
- Zero downtime during deployments
- Instant rollback if new model performs poorly
- A/B testing between model versions
- Risk mitigation through gradual traffic shifts
Deployment process:
- Deploy green environment with new model/prompt configuration
- Run automated tests against green environment
- Gradually shift traffic: 90/10 → 70/30 → 50/50 → 30/70 → 0/100
- Monitor key metrics during each shift
- Rollback instantly if metrics degrade
Infrastructure setup:
- Two deployments (blue-model-v1, green-model-v2)
- Load balancer with weighted routing
- Shared Redis cache and database
- Independent monitoring for each environment
Traffic shifting strategy:
- Week 1: 100% blue, 0% green (baseline)
- Week 2: 90% blue, 10% green (canary)
- Week 3: 70% blue, 30% green (ramp up)
- Week 4: 50% blue, 50% green (A/B test)
- Week 5: 30% blue, 70% green (phase out old model)
- Week 6: 0% blue, 100% green (full deployment)
What to monitor during shifts:
- Response quality scores (user feedback)
- Response latency (P95, P99)
- Error rates by environment
- Cost per request
- User satisfaction metrics
Real-world gotchas:
- State management: Ensure user conversations don't get split between environments (in your Load Balancer you wan't to make sessions sticky to certain images, so individual users are always routed to the same place)
- Cache warming: New environment starts with cold cache (preload some common data into your cache, or dup your old cache into the new environment)
- Cost implications: Running two environments doubles infrastructure costs temporarily (the traffic shifting strategy duration, e.g. from weeks to days, depend on how tolerable the cost is to your operation)
- Model compatibility: Ensure new model can handle existing user data formats (sometimes a new model may require additional data that is not provided yet, so remember to connect this to clients only when they're ready to use the latest version)
When to rollback immediately:
- Error rate increases >2x baseline
- Response latency increases >30%
- User complaints spike
- Cost per request exceeds budget thresholds
- Security incidents detected
LLM Production Failure Modes
Now everything I've covered is mostly focused on a broader approach for managing AI systems in production environments. LLMs are a different beast. Let me save you weeks of debugging. Here are the failure modes that actually hit LLM systems in production:
API Rate Limit Death Spirals
The Problem: OpenAI hits you with rate limits, your system retries aggressively, making things worse.
Most teams handle this wrong:
# BAD - Creates death spiral
async def call_llm(prompt):
for attempt in range(5):
try:
return await openai.chat.completions.create(messages=[{"role": "user", "content": prompt}])
except RateLimitError:
await asyncio.sleep(1) # Fixed backoff makes it worseThe Fix: Exponential backoff with circuit breakers and fallback models.
import asyncio
import random
import time
from enum import Enum
from typing import Optional, Dict, Any
from dataclasses import dataclass
import openai
from openai import RateLimitError, APIError, APITimeoutError
class CircuitState(Enum):
CLOSED = "closed" # Normal operation
OPEN = "open" # Failures detected, blocking requests
HALF_OPEN = "half_open" # Testing if service recovered
@dataclass
class CircuitBreakerConfig:
failure_threshold: int = 5 # Failures before opening circuit
recovery_timeout: int = 60 # Seconds before trying half-open
success_threshold: int = 3 # Successes needed to close from half-open
@dataclass
class BackoffConfig:
base_delay: float = 1.0 # Base delay in seconds
max_delay: float = 60.0 # Cap on delay
multiplier: float = 2.0 # Exponential multiplier
jitter: bool = True # Add randomization
class CircuitBreaker:
def __init__(self, config: CircuitBreakerConfig):
self.config = config
self.state = CircuitState.CLOSED
self.failure_count = 0
self.success_count = 0
self.last_failure_time = 0
def can_execute(self) -> bool:
if self.state == CircuitState.CLOSED:
return True
elif self.state == CircuitState.OPEN:
if time.time() - self.last_failure_time > self.config.recovery_timeout:
self.state = CircuitState.HALF_OPEN
self.success_count = 0
return True
return False
else: # HALF_OPEN
return True
def record_success(self):
if self.state == CircuitState.HALF_OPEN:
self.success_count += 1
if self.success_count >= self.config.success_threshold:
self.state = CircuitState.CLOSED
self.failure_count = 0
elif self.state == CircuitState.CLOSED:
self.failure_count = 0
def record_failure(self):
self.failure_count += 1
self.last_failure_time = time.time()
if self.state == CircuitState.CLOSED:
if self.failure_count >= self.config.failure_threshold:
self.state = CircuitState.OPEN
elif self.state == CircuitState.HALF_OPEN:
self.state = CircuitState.OPEN
class ExponentialBackoff:
def __init__(self, config: BackoffConfig):
self.config = config
self.attempt = 0
def reset(self):
self.attempt = 0
def next_delay(self) -> float:
if self.attempt == 0:
delay = 0
else:
delay = min(
self.config.base_delay * (self.config.multiplier ** (self.attempt - 1)),
self.config.max_delay
)
if self.config.jitter:
# Add ±25% jitter to prevent thundering herd
jitter = delay * 0.25 * (2 * random.random() - 1)
delay = max(0, delay + jitter)
self.attempt += 1
return delay
class RobustLLMClient:
def __init__(
self,
client: openai.AsyncOpenAI,
circuit_config: Optional[CircuitBreakerConfig] = None,
backoff_config: Optional[BackoffConfig] = None,
max_retries: int = 5
):
self.client = client
self.circuit_breaker = CircuitBreaker(circuit_config or CircuitBreakerConfig())
self.backoff_config = backoff_config or BackoffConfig()
self.max_retries = max_retries
async def call_llm(
self,
messages: list[Dict[str, Any]],
model: str = "gpt-4",
**kwargs
) -> Optional[Any]:
"""
Robust LLM call with exponential backoff and circuit breaker.
Returns None if circuit is open or all retries exhausted.
"""
if not self.circuit_breaker.can_execute():
raise Exception(f"Circuit breaker is {self.circuit_breaker.state.value}")
backoff = ExponentialBackoff(self.backoff_config)
last_exception = None
for attempt in range(self.max_retries + 1):
try:
# Wait before retry (except first attempt)
delay = backoff.next_delay()
if delay > 0:
await asyncio.sleep(delay)
# Make the API call
response = await self.client.chat.completions.create(
model=model,
messages=messages,
**kwargs
)
# Success - reset circuit breaker
self.circuit_breaker.record_success()
return response
except (RateLimitError, APITimeoutError) as e:
# Retryable errors
last_exception = e
self.circuit_breaker.record_failure()
if attempt == self.max_retries:
break
print(f"Attempt {attempt + 1} failed with {type(e).__name__}: {e}")
continue
except (APIError, Exception) as e:
# Non-retryable errors - fail fast
self.circuit_breaker.record_failure()
raise e
# All retries exhausted
self.circuit_breaker.record_failure()
raise last_exception or Exception("Max retries exceeded")
# Usage example
async def main():
client = openai.AsyncOpenAI(api_key="your-key-here")
# Configure for production use
circuit_config = CircuitBreakerConfig(
failure_threshold=3, # Open after 3 failures
recovery_timeout=30, # Try recovery after 30s
success_threshold=2 # Need 2 successes to fully recover
)
backoff_config = BackoffConfig(
base_delay=0.5, # Start with 500ms
max_delay=30.0, # Cap at 30 seconds
multiplier=2.0, # Double each time
jitter=True # Add randomization
)
robust_client = RobustLLMClient(
client=client,
circuit_config=circuit_config,
backoff_config=backoff_config,
max_retries=4
)
try:
response = await robust_client.call_llm(
messages=[{"role": "user", "content": "Hello!"}],
model="gpt-4",
temperature=0.7
)
print(response.choices[0].message.content)
except Exception as e:
print(f"Failed after all retries: {e}")
# For high-throughput scenarios, use a global circuit breaker
class GlobalCircuitBreaker:
_instances: Dict[str, CircuitBreaker] = {}
@classmethod
def get_circuit(cls, service_name: str, config: CircuitBreakerConfig) -> CircuitBreaker:
if service_name not in cls._instances:
cls._instances[service_name] = CircuitBreaker(config)
return cls._instances[service_name]
if __name__ == "__main__":
asyncio.run(main())Why this actually works:
- Circuit breakers: Stop calling APIs that are consistently failing
- Request queuing: Batch requests instead of hammering APIs
- Rate limit budgeting: Distribute requests across time windows
You can additionaly have intelligent fallback chains, e.g. GPT-4.1 → GPT-3.5 → Local model → Error.
Context Window Overflow Catastrophes
The Problem: Your agent system hits context limits mid-conversation and everything breaks.
Common scenarios:
- Long document analysis that exceeds the max amount of tokens
- Agent conversations that grow beyond context windows
- RAG systems that inject too much retrieved content
- Multi-turn conversations that accumulate context
The Fix: Context window management strategies.
Context management patterns:
- Sliding window: Keep last N messages, summarize the rest
- Intelligent truncation: Remove least important context first
- Context compression: Summarize old content to preserve key information
- Context partitioning: Break large tasks into smaller chunks
Agent Workflow Reliability Issues
The Problem: Multi-step agent workflows fail unpredictably, leaving tasks half-completed.
Where agent systems break:
- Function calling failures: LLM generates malformed JSON parameters
- Tool integration timeouts: External APIs don't respond
- State management issues: Agent loses track of what it was doing
- Error propagation: One failed step cascades through entire workflow
The Fix: Agent workflow patterns that handle failures gracefully.
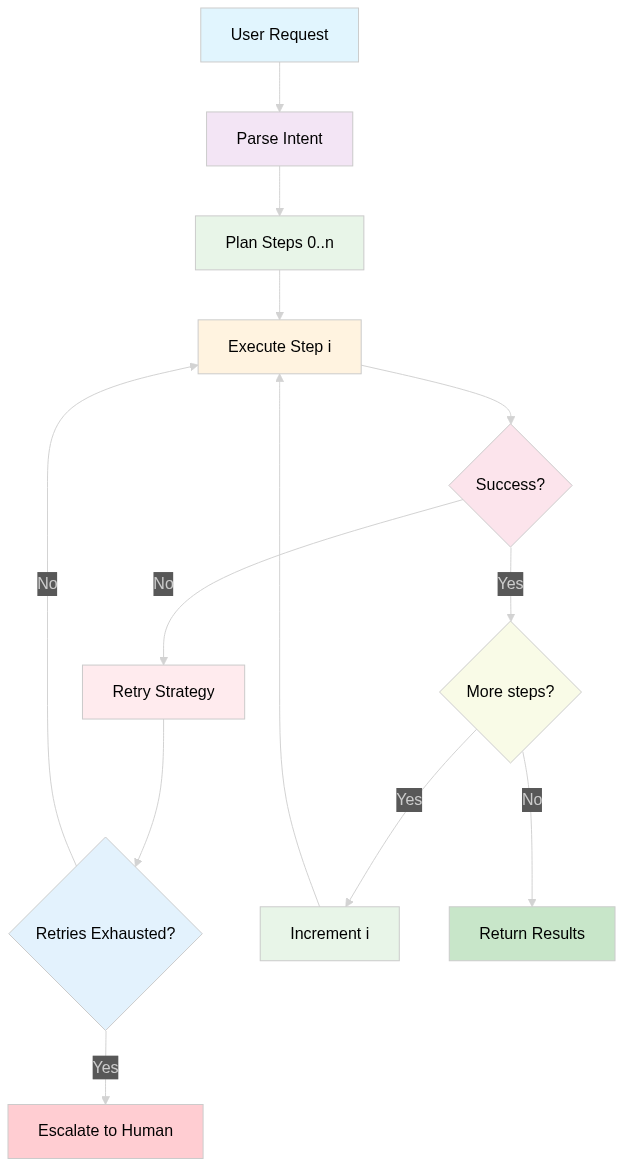
Prompt Injection and Security Failures
The Problem: Users figure out how to manipulate your prompts and break your system.
Common attack vectors:
- Direct prompt injection: "Ignore previous instructions and..."
- Indirect injection: Through uploaded documents or user data
- Jailbreaking: Getting models to output prohibited content
- Data exfiltration: Tricking models into revealing system prompts
The Fix: Defense-in-depth security patterns.
Security checklist for LLM systems:
- Input sanitization before prompt construction
- Output filtering for sensitive information
- Separate system and user contexts
- Monitoring for injection attempt patterns
- Rate limiting per user/IP
- Content policy enforcement
Practical Defense Strategies:
1. Prompt Architecture Defense
Instead of mixing system instructions with user input in a single prompt, use structured prompt separation:
- System context: Your instructions to the AI (isolated from user input)
- User context: User data wrapped in clear delimiters like XML tags or JSON structures
- Output constraints: Explicit formatting requirements that make injection harder
When user input tries to "break out" of its designated section, the model treats it as data rather than instructions. This architectural separation is your first line of defense.
2. Input Validation Layers
Pre-processing filters:
- Block obvious injection patterns ("ignore previous", "system:", "you are now", etc.)
- Detect suspicious formatting (excessive special characters, encoding attempts)
- Implement length limits that prevent overwhelming system prompts
- Verify file types for uploads (ensure PDFs are actually PDFs, not text files with injection attempts)
Content analysis approach:
- Use a secondary LLM specifically trained to detect manipulation attempts
- Flag inputs that seem designed to confuse or redirect the main model
- Monitor for repeated similar attempts from the same user or IP
3. Output Sanitization
Response filtering:
- Scan outputs for system prompt leakage (internal instructions appearing in responses)
- Remove any internal system information that shouldn't be user-visible
- Block responses containing obvious signs of successful jailbreaking
Sanity checking:
- If the model's response seems completely unrelated to the user's question, it might indicate successful injection
- Implement "reasonableness checks"—does this response make sense given the input context?
- Monitor response length and content type for sudden anomalies
4. Session and User Isolation
Context management:
- Keep each user's conversation isolated from others
- Clear session state regularly to prevent context pollution
- Don't let one user's injection attempts affect others
Privilege separation:
- Different user tiers (admin, verified, guest) get different prompt templates
- Sensitive operations require additional authentication steps
- Limit certain features to verified accounts only
5. Detection and Monitoring
Pattern recognition:
- Log all user inputs and flag suspicious patterns automatically
- Monitor users who repeatedly attempt injection techniques
- Alert when the success rate of "unusual" requests spikes across your system
Business impact tracking:
- Track when responses seem inappropriate or off-topic
- Monitor user complaints about unexpected bot behavior
- Watch for sudden changes in average response characteristics
6. Human Oversight Integration
Escalation workflows:
- When injection detection triggers, route requests to human review queues
- For sensitive topics, require human approval before responding
- Implement user reporting mechanisms for inappropriate responses
Regular security auditing:
- Have security teams regularly test your system with known attack patterns
- Review logs monthly for successful injections you might have missed
- Update defenses based on emerging attack techniques in the community
7. Gradual Deployment and Circuit Breakers
Staged rollouts:
- Never deploy new LLM features directly to all users
- Start with internal testing, then limited user groups
- Monitor closely during rollouts for behavioral anomalies
Automatic safeguards:
- If injection success rate crosses a threshold, automatically revert to a safer prompt version
- Have "safe mode" responses ready when systems detect ongoing attacks
- Maintain quick rollback capabilities for when defenses fail
The Reality Check:
Prompt injection isn't just a technical problem—it's an adversarial game. Users will always find new ways to break your system. The goal isn't preventing all attacks (impossible), but making attacks harder, detecting them faster, and limiting damage when they succeed.
Most importantly: Assume your defenses will eventually be bypassed. Build systems that recover gracefully when attacks succeed, rather than systems that assume they're invulnerable. Your security posture should be "when we get compromised" not "if we get compromised."
The companies that survive prompt injection attacks are those that plan for failure, not those that believe their defenses are perfect.
LLM Cost Management (Where Money Actually Disappears)
Your localhost demo costs nothing. Production LLM systems can burn 10k in a month easily if not managed properly.
The Real Cost Killers
Token waste at scale:
- Redundant API calls for identical requests
- Inefficient prompt construction (too much context)
- Using expensive models for simple tasks
- No caching strategy for repeated computations
Agent cost explosion:
- Agents making unnecessary tool calls
- Deep recursive thinking chains
- Retry loops that multiply API costs
- No cost limits per user session
What Actually Controls LLM Costs
Intelligent model routing:
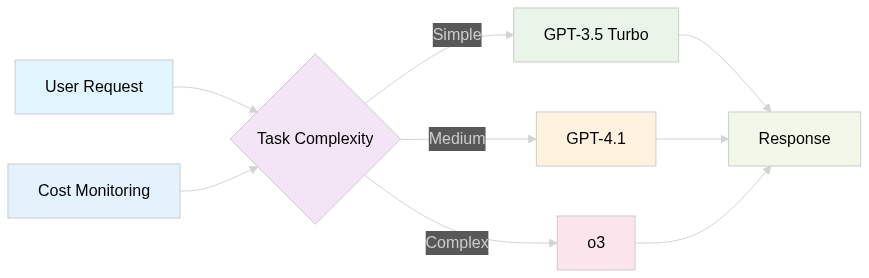
Cost optimization strategies that work:
- Response caching: Cache identical/similar requests
- Prompt optimization: Remove unnecessary tokens from system prompts
- Smart batching: Combine multiple requests where possible
- Cost budgets: Set spending limits per user/session
- Usage analytics: Track cost per feature/user to identify waste
Cost monitoring dashboard essentials:
- Daily/monthly API spend by model
- Cost per user conversation
- Most expensive operations/prompts
- Cache hit rates by request type
- Model usage distribution
The Bottom Line: Building LLM Systems That Actually Work
The difference between LLM demos and production systems isn't sophistication—it's handling the chaos of real users and unreliable external APIs.
Success factors for production LLM systems:
- Assume APIs Will Fail: Build fallbacks and graceful degradation plans from day one
- Monitor User Experience: Technical uptime means nothing if responses are garbage, include in the user in the loop
- Control Costs Proactively: Set budgets and alerts before bills surprise you
- Plan for Prompt Injection: Security isn't optional when users can clearly control inputs and behavior of your system
- Design for Context Limits: Context windows will overflow, plan for it
What separates successful LLM deployments from expensive failures:
Successful teams:
- Treat LLM APIs like unreliable external services
- Monitor business metrics (user satisfaction, task completion), not just uptime
- Implement cost controls and budgets from the start
- Plan for security attacks and edge cases
Failed teams:
- Assume LLM APIs will always work perfectly
- Only monitor traditional infrastructure metrics
- Discover cost problems after getting the bill
- Ignore security until after they get compromised
The final check: If your LLM system can't handle a user trying to inject malicious prompts while you're hitting rate limits at 3 AM on a Sunday, it's not ready for production.
Most importantly, remember that users don't care about your sophisticated prompt engineering. They care about getting reliable, helpful responses quickly. Build your infrastructure to deliver that consistently, and everything else is just implementation details.
Now go build systems that actually work in production, not just in demos.


Comments ()